
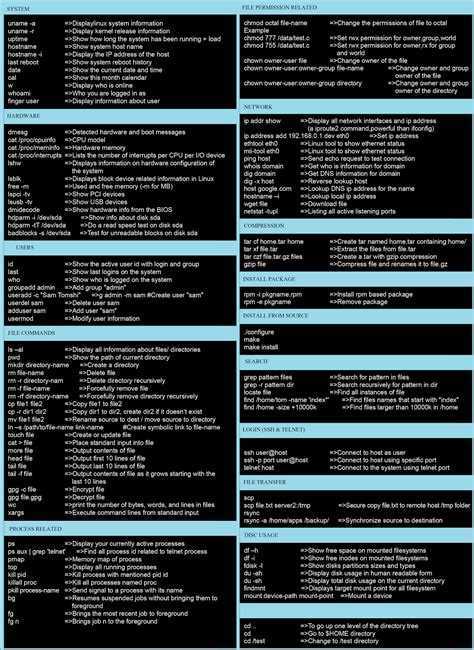
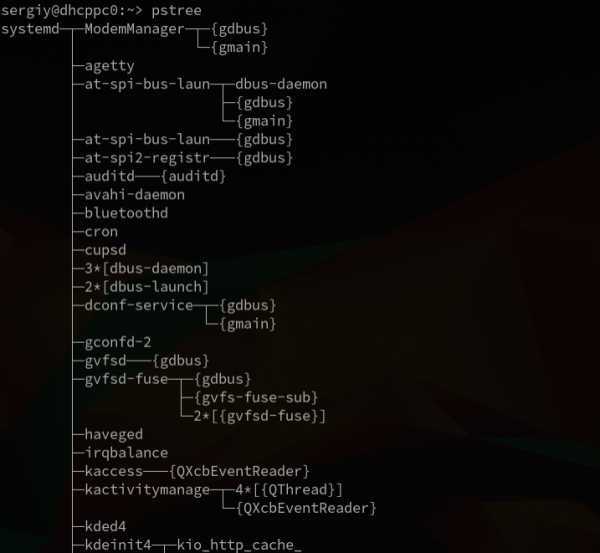
Запуск программы
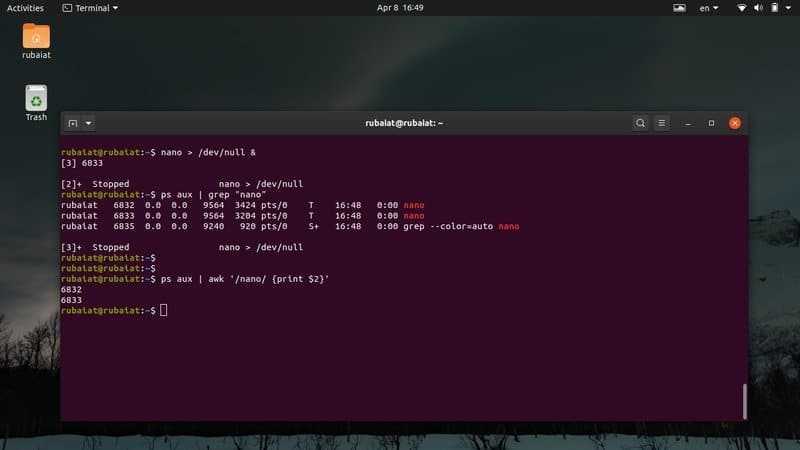
В оперативной памяти процесса находятся код и данные, загруженные из файла. При запуске программы из командной строки, обычно создается новый процесс и в его память загружается файл с программой. Загрузка файла делается вызовом одной из функций семейства exec (см. ). Функции отличаются способом передачи параметров, а также тем, используется ли переменная окружения PATH для поиска исполняемого файла. Например execl в качестве первого параметра принимает имя исполняемого файла, вторым и последующими – строки аргументы, передаваемые в argv[], и, наконец, последний параметр должен быть NULL, он дает процедуре возможность определить, что параметров больше нет.
Пример с двумя ошибками:
Ошибка 1:
Первый аргумент передаваемый программе это имя самой программы. В данном примере в списке процессов будет видна программа с именем -l, запущенная без параметров.
Ошибка 2:
Поскольку код из файла будет загружен в текущий процесс, то старый код и данные, в том числе будет затерты. Первый не сработает никогда.
Команда chmod
Команда chmod используется для управления разрешениями на заданный файл/каталог.
Например, при первом запуске бинарного файла приложения (или скрипта) на вашем компьютере, может появиться сообщение об ошибке типа «Отказано в доступе». Выполнив при помощи уже знакомой нам команды проверку установленных разрешений, мы наблюдаем следующую картину:
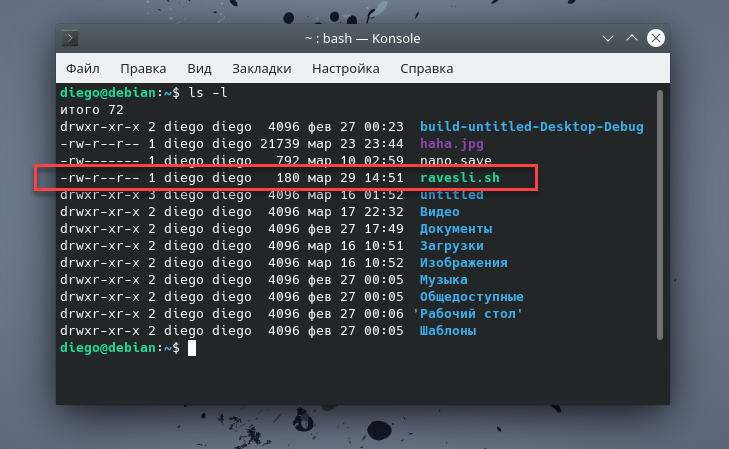
Как видите, у отсутствуют права на выполнение (символ в наборе разрешений). В такой ситуации нам поможет команда , которая добавляет (или убирает) необходимые разрешения, обеспечивающие пользователю возможность запускать скрипт (или двоичный файл):
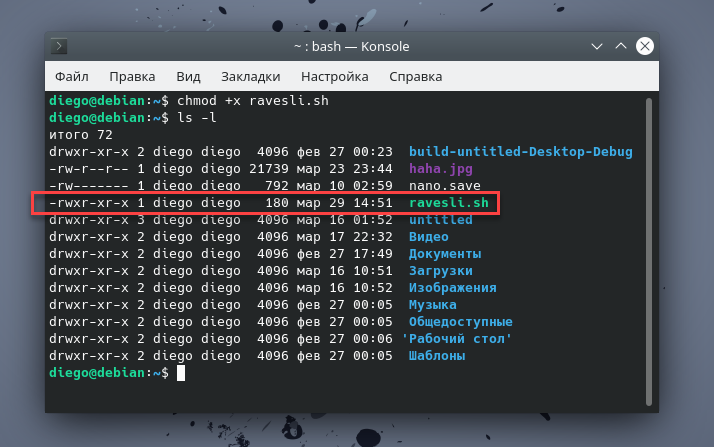
После этого, при повторной попытке выполнить скрипт ravesli.sh, вы больше не получите ранее описанного сообщения об ошибке.
Как исключить файлы, открытые определённым пользователем
Чтобы исключить файлы, которые были открыты пользователем, используйте оператор ^. Исключение пользователей из списка облегчает поиск интересующей вас информации. Вы должны использовать опцию -u, как и раньше, и добавить символ ^ в начале имени пользователя.
sudo lsof -u ^mial
Отрицание (поиск любых значений, кроме приведённых) можно применять с любыми опциями, для которых можно указать какое-либо значение, то есть с именами пользователей, именами команд, идентификаторами процессов, папками и т.д.
Например, чтобы показать все файлы, которые были открыты в директории /home, но которые открыты процессами, не принадлежащими пользователю mial:
sudo lsof +D /home -u ^mial
Синтаксис команды tr в Linux
Программа обрабатывает текст посимвольно. По умолчанию у её синтаксиса следующий вид (квадратные скобки указывают, что аргумент не обязателен):
tr … НАБОР1
Всего доступно 4 ключа для уточнения операции над символами:
| Ключ | Длинный вариант | Значение |
| -c, -C | —complement | Сначала получить дополнение НАБОРА1 |
| -d | —delete | Удалить знаки из НАБОРА2, не превращать |
| -s | —squeeze-repeats | Замещать последовательность знаков, которые повторяются, из перечисленных в последнем НАБОРЕ, на один такой знак |
| -t | —truncate-set1 | Сначала сократить НАБОР1 до размеров НАБОРА2 |
НАБОРЫ указываются как символьные строки. В большинстве случаев символы представляют сами себя. Полный набор опций представлен в следующей таблице:
| Опция | Значение |
| \HHH | Знак в восьмеричной кодировке (с трех цифр ННН) |
| \\ | Обратный слэш |
| \b | Забой |
| \f | Перевод страницы |
| \n | Начать с новой строки |
| \r | Возврат каретки |
| \t | Горизонтальная табуляция |
| \v | Вертикальная табуляция |
| ЗНАК1-ЗНАК2 | Все знаки от ЗНАК1 до ЗНАК2 в порядке возрастания |
| ЗНАК заполняет НАБОР2 до длины НАБОРА1 | |
| Указанное ЧИСЛО одинаковых ЗНАКОВ; ЧИСЛО восьмиричных, если начинается с 0 | |
| Все буквы и цифры | |
| Все буквы | |
| Все горизонтальные пробельные символы | |
| Все управляющие знаки | |
| Все цифры | |
| Все печатаемые знаки, исключая пробел | |
| Все маленькие буквы | |
| Все печатаемые знаки, включая пробел | |
| Все знаки пунктуации | |
| Все вертикальные и горизонтальные пробельные знаки | |
| Все большие буквы | |
| Все шестнадцатиричные цифры | |
| Все знаки, эквивалентные ЗНАКУ |
Превращение осуществляется, если не указано -d для обоих НАБОРОВ. -t можно использовать только во время превращения. Если нужно, НАБОР2 будет расширен до размеров НАБОРА1 повторением последнего символа. Лишние символы НАБОРА2 будут пропущены. Гарантированно расширяются в порядке возрастания только и . Использованные символы в НАБОРЕ2 во время превращения можно применять для определения превращения регистра только в парах. -s использует последний указанный набор. Уплотнение происходит после превращения или удаления.
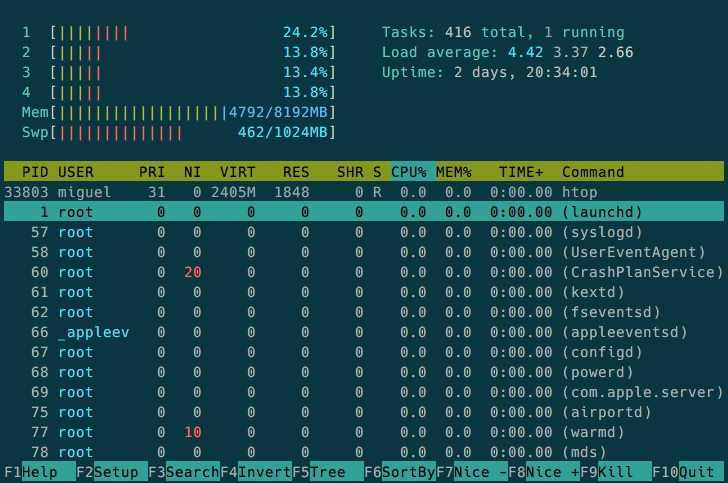
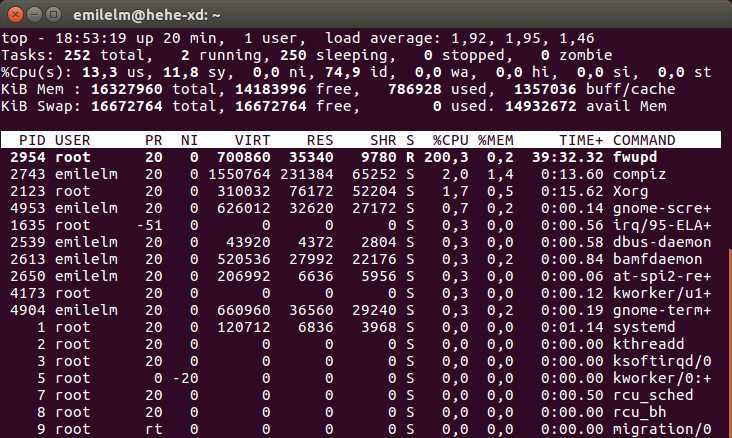
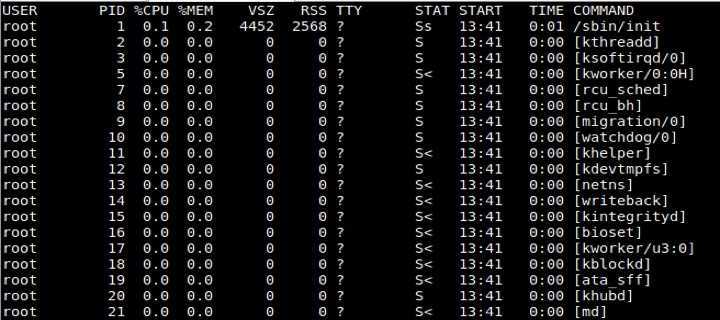
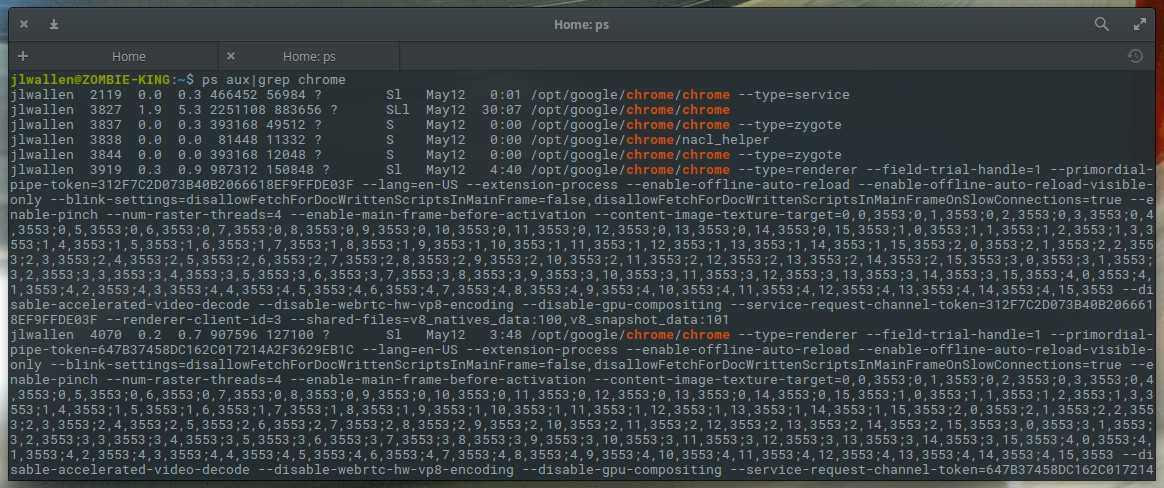
Расшифровка столбцов
- PID
- USER
- PR
- NI
- VIRT — (kb — килобайты). Общее количество виртуальной памяти, используемой программой. VIRT = SWAP + RES.
- RES — (kb). Количество резидентной (не перемещаемой в swap) памяти. RES = CODE + DATA.
- SHR — (kb). Количество разделяемой (shared) памяти программы.
- S — статус процесса.
- %CPU
- %MEM
- TIME+
- COMMAND
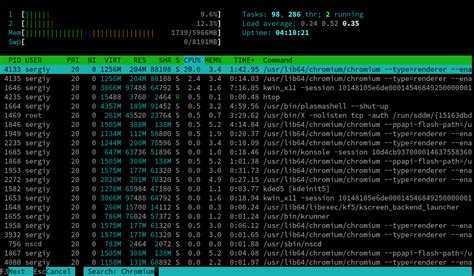
htop
Homepage: htop
Htop – основанный на ncurses просмотрщик процессов подобный top, htop, atop интерактивные просмоторщики процессов, но позволяющий прокручивать список процессов вертикально и горизонтально, чтобы видеть их полные параметры запуска. Управление процессами (остановка, изменение приоритета) может выполняться без ручного ввода их идентификаторов.
Htop экономит одну колонку и показывает в колонке PID(процесс) то, что Использование ps для мониторинга процессов (ps -eLf) показывает в колонке LWP(поток; процесс — контейнер для потоков)
htop в CentOS теперь CentOS Stream установка из репозитория см. rpm# wget http://download.fedora.redhat.com/pub/epel/5/x86_64/htop-0.8.3-1.el5.x86_64.rpm
# rpm -i htop-0.8.3-1.el5.x86_64.rpm
Замечания к BSD системам, при использовании htop
При установки htop на FreeBSD требует смонтированную систему linprocfs, для совместимости с Linux. linprocfs — the Linux process file system, or linprocfs, emulates a subset of Linux’ process file system and is required for the complete operation of some Linux binaries.



> man linprocfs ... > mount -t linprocfs linproc /compat/linux/proc > df -h ... linprocfs 4.0K 4.0K 0B 100% /usr/compat/linux/proc > cd /usr/ports/sysutils/htop > make install clean
Скрипт для монтирования linprocfs при загрузки FreeBSD:
> ee usrlocaletcrc.d0start.sh #! /bin/sh #for htop sbinmount -t linprocfs linproc compatlinuxproc
Или прописать в fstab строку и для проверки примонтировать командой mount linproc
linproc /usr/compat/linux/proc linprocfs rw 0 0
Команда netstat
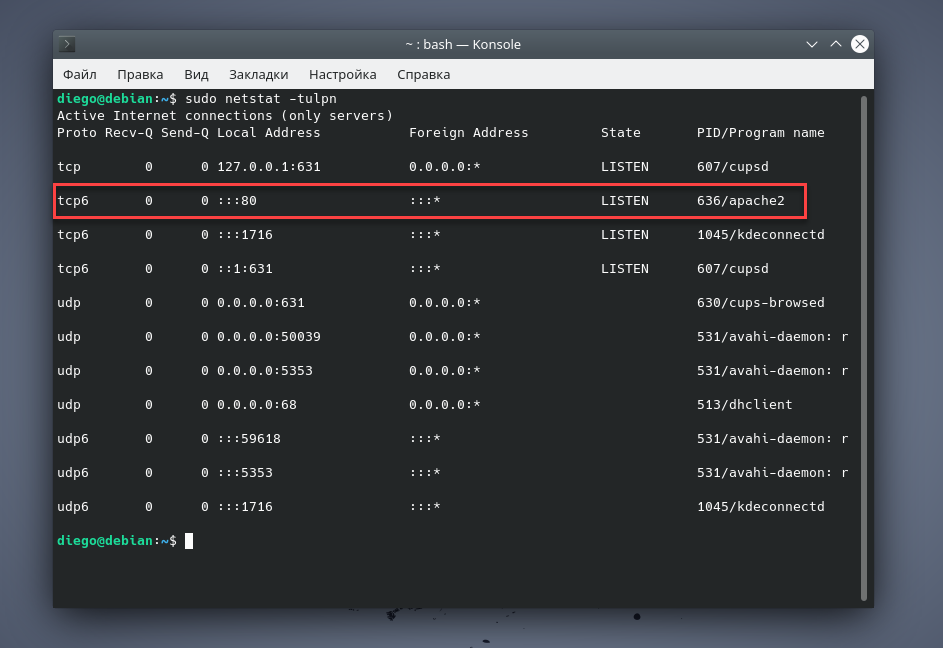
Команда netstat отображает информацию о состоянии сети. Она показывает используемые сетевые порты и входящие соединения к ним. Однако стоит заметить, что команда не входит в базовую поставку Linux; утилита устанавливается вместе с пакетом net-tools.
Предположим, вы проводите локальные эксперименты со своей программой, принимающей входящие подключения от других программ. Может случиться так, что вы получите сообщение об ошибке типа «Необходимый вам порт (или адрес) уже занят». Применив команду с параметрами протокола, процесса и порта, мы увидим, что HTTP-сервер Apache уже использует 80 порт на нижеприведенном хосте:
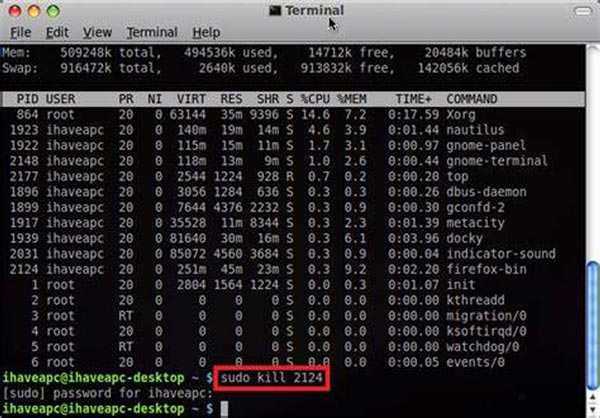
Завершаем процессы в Linux
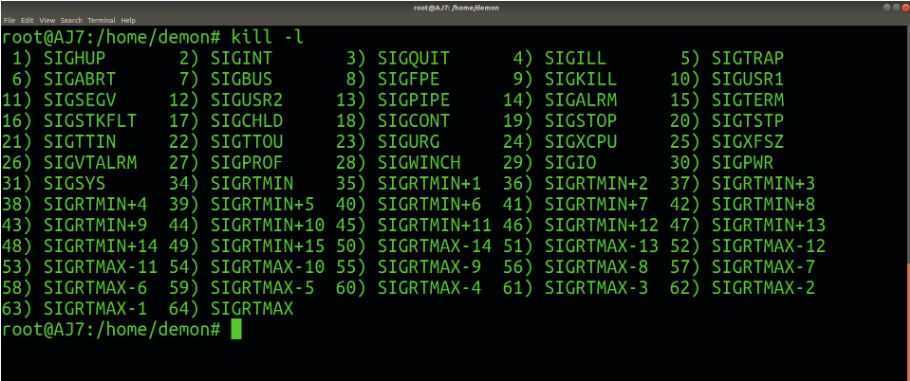
Существуют разные системные средства, позволяющие «убить» какой-либо процесс. Иногда для этого приходится узнавать его идентификатор, а в других ситуациях достаточно только названия. Далее мы предлагаем детально изучить все представленные методы, чтобы найти оптимальный для себя и выполнять его при необходимости, учитывая описанные ранее сигналы.
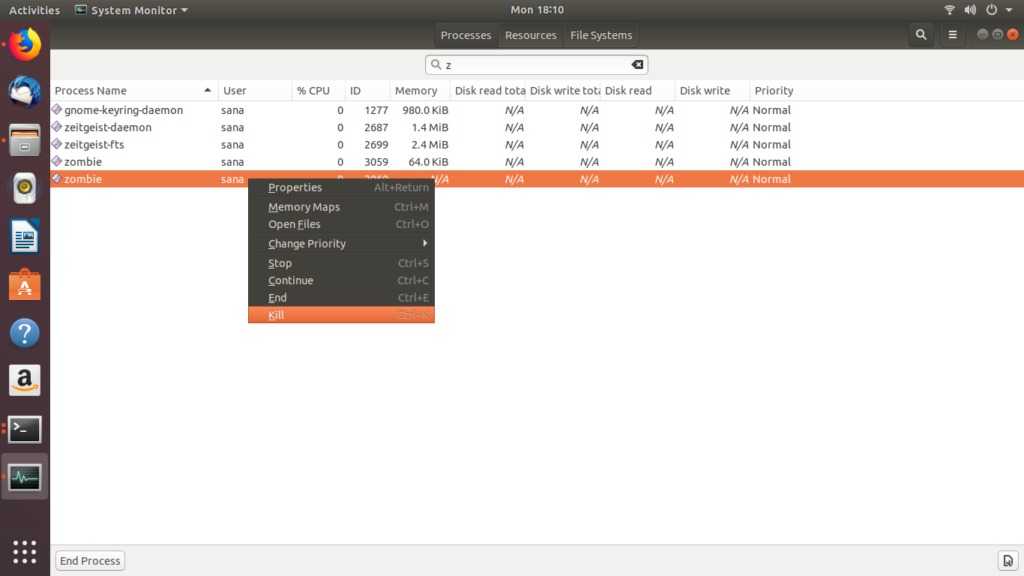
Способ 1: «Системный монитор»
Начнем с самого простого, но менее вариативного метода, который осуществляется через программу графического интерфейса и будет полезен тем пользователям, кто просто хочет завершить процесс, не прибегая при этом к запуску терминальных команд. Рассмотрим эту операцию на стандартной оболочке дистрибутива Ubuntu.
- Перейдите в меню «Показать приложения», где отыщите «Системный монитор» и запустите его, кликнув по значку левой кнопкой мыши.
В появившемся окне вы увидите список процессов. Найдите имя необходимой для завершения задачи.
Дополнительно вы можете переместиться в свойства объекта через контекстное меню, чтобы посмотреть всю информацию о нем.
Щелкните правой кнопкой мыши по строке и выберите пункт «Завершить». Это же действие выполняется через горячую клавиш Ctrl + E. Еще внизу имеется кнопка, позволяющая завершить процесс без вызова контекстного меню.
Если же операция не завершилась по каким-либо причинам, задействуйте опцию «Убить».
Ознакомьтесь с информацией в предупреждении и подтвердите свои намерения.
В преимущественном большинстве графических оболочек системный монитор реализован похожим образом, поэтому каких-то проблем с пониманием интерфейса возникнуть не должно.
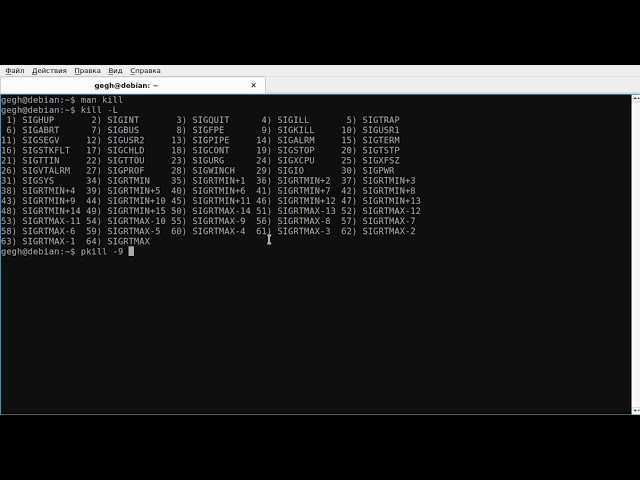
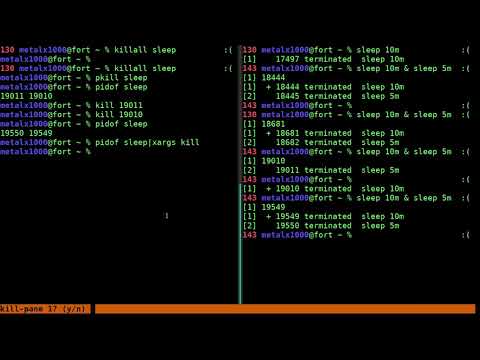
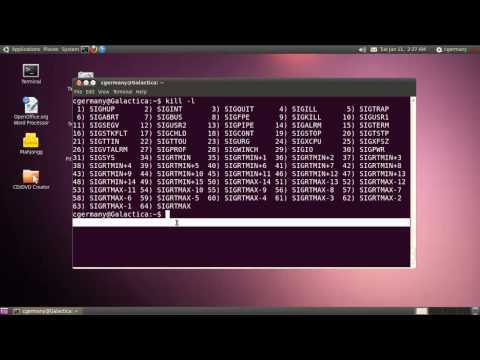
Способ 2: Команда kill
Для применения команды kill потребуется знание PID (идентификатора процесса), поскольку именно так осуществляется применение аргументов. В статье ниже мы детально описали операцию просмотра списка процессов для получения различной информации. Обязательно ознакомьтесь с ней перед выполнением следующей инструкции.
Подробнее: Просмотр списка процессов в Linux
Далее остается только запустить «Терминал» и задействовать упомянутую команду. Для начала изучите ее простой синтаксис: . Теперь давайте рассмотрим пример «убийства».
- Откройте меню приложений и запустите «Терминал».
Введите простую команду для получения информации об указанном процессе, где name — имя желаемой программы.
В отобразившемся результате отыщите главный PID и запомните его.
Введите для завершения процесса через сигнал SIGTERM. Вместо PID вам нужно написать определенный ранее номер идентификатора.
Теперь вы можете снова использовать , чтобы проверить, была ли завершена операция.
То же самое действие по «убийству» осуществляется и через другой аргумент путем ввода .
Если приведенные выше команды не принесли никакого результата, потребуется обозначить сигнал SIGKILL, вставив команду .
Учтите, что некоторые процессы запускаются от имени суперпользователя, соответственно, для их завершения требуются привилегии. Если при попытке ввода kill вы получаете информацию «Отказано в доступе», вводите перед основной командой sudo, чтобы получилось .

![Top, htop, atop интерактивные просмоторщики процессов [айти бубен]](https://smartshop124.ru/wp-content/uploads/8/9/4/894230ed0559026a7b5fcfa2a1316ebc.jpeg)

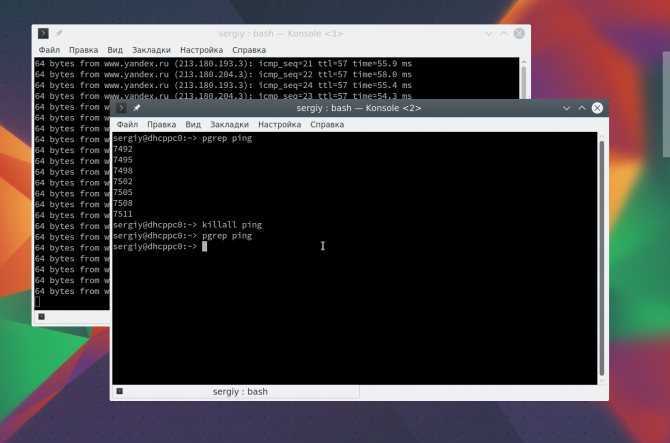
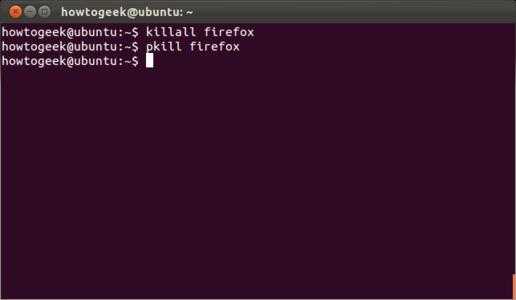
Способ 3: Команда pkill
Следующая консольная утилита называется pkill и является модернизированной версией предыдущей команды. Здесь все реализовано точно по такому же образу, но вместо PID от пользователя требуется вводить название процесса.
- Для отправки сигнала SIGTERM используйте .
После вы можете убедиться, что операция была успешно завершена.
Задайте вручную тип сигнала, введя такую форму , где -TERM — необходимый сигнал.
Используйте для определения того, что процесс больше не выполняется, если вы не хотите задействовать ps
Способ 4: Команда killall
В качестве последнего способа мы рассмотрим команду под названием killall. Ее функционирование и синтаксис выглядят точно так же, как у всех предыдущих утилит, поэтому останавливаться на этом мы не будем. Только уточним, что эта команда позволяет завершить все процессы с указанным названием разом и может быть использована в разных случаях.
Теперь вы знаете все о завершении процессов в Linux. Перед выполнением методов убедитесь, что принудительное «убийство» не приведет к системным сбоям. Если же ни один вариант не позволил полностью избавиться от процесса, попробуйте просто перезагрузить компьютер или удалить софт, связанный с этой опцией.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
htop
В отличие от top, утилиту htop сначала необходимо установить на сервер:
Ubuntu / Debian:
apt-get install htop
CentOS:
yum install htop
И после запустить:
htop
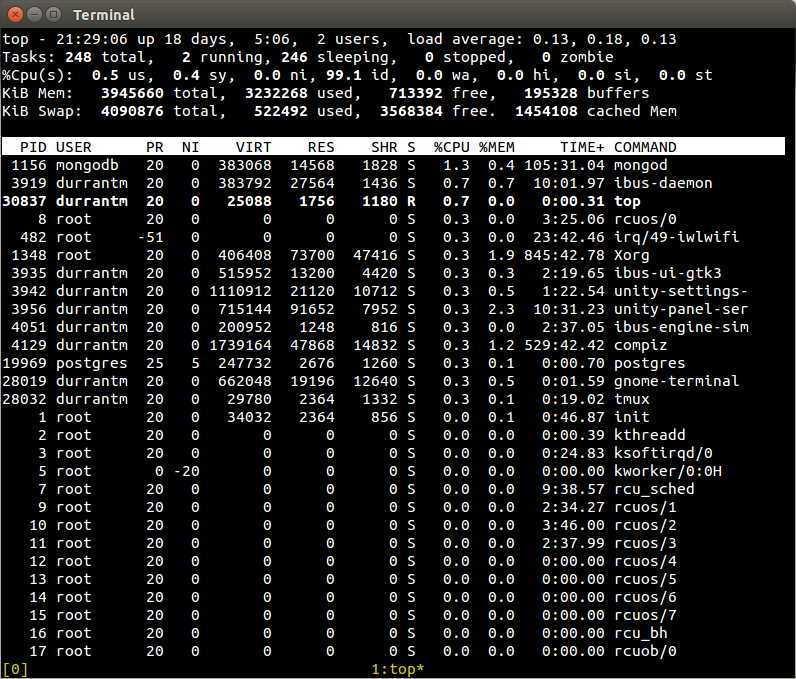
Вывод команды выглядит следующим образом:
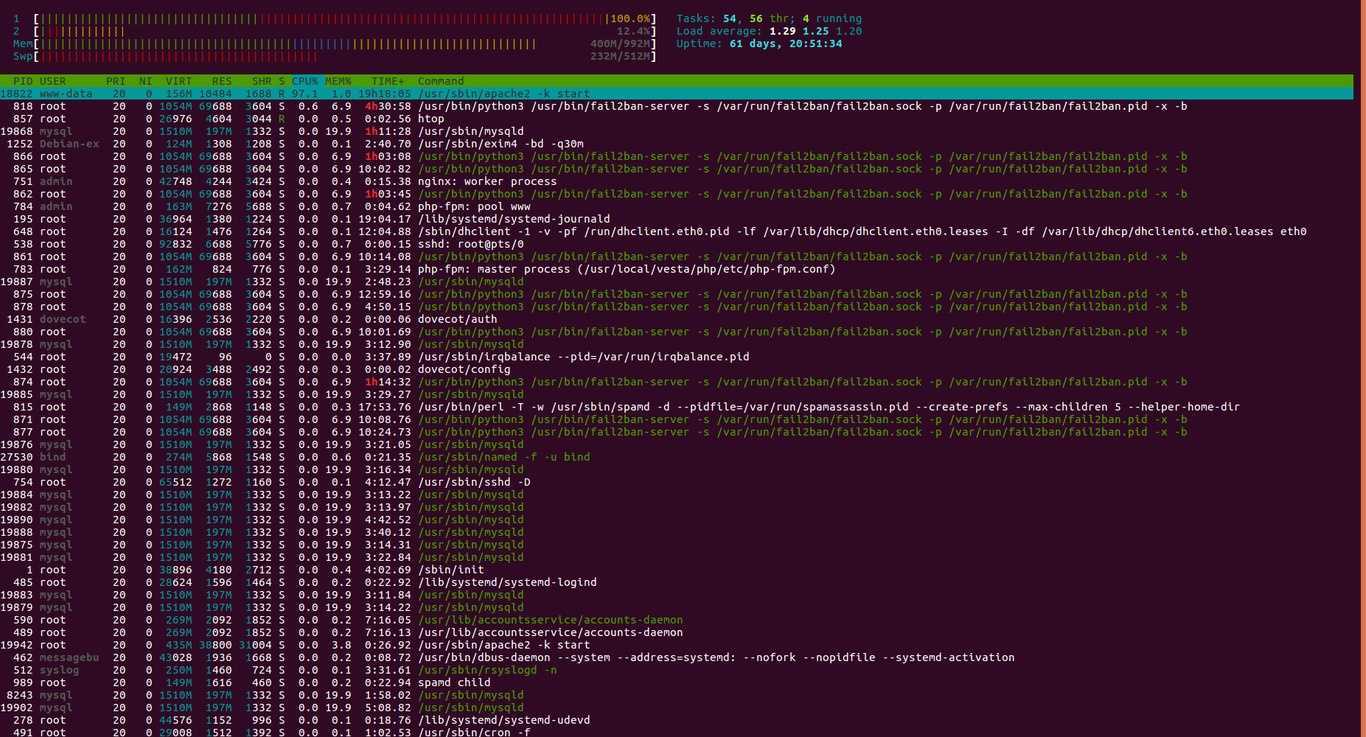
Сверху слева вы можете видеть данные о нагрузке каждого ядра процессора, объем занятой памяти, сведения о количестве процессов, значения load avearage (средней нагрузки) за последние 1, 5 и 15 минут и аптайм системы.
По умолчанию процессы отсортированы по уровню нагрузки на процессор, от большего к меньшему.
Чтобы отсортировать их по занятой памяти (или любому другому параметру), просто кликните на название нужного столбца, например MEM. Для обратной сортировки (от меньшего к большему) достаточно кликнуть на тот же столбец еще раз. Также для управления сортировкой можно использовать клавиши M (сортировка по памяти), P (по процессору), T (по времени), аналогично утилите top.
Дополнительно используются:
Пробел — отметить процесс (таким образом можно помечать процессы для групповой операции с ними, например, завершения).
u — вывести процессы конкретного пользователя.
Для управления используются клавиши F1 — F10:
F1 — вывод справки
F2 — настройка вывода (добавление, удаление столбцов, отображение расширенной информации в верхнем блоке и пр.)
F3 — поиск процессов
F4 — фильтрация процессов (вывод процессов, имеющих в названии указанное слово)
F5 — вывод дерева процессов (родительские и дочерние процессы)
F6 — изменить тип сортировки
F7 / F8 — повышение / понижение приоритета
F9 — завершение процесса (в отличие от top, не требуется указание PID — просто выделите с помощью мыши или клавиатуры нужный процесс и нажмите F9. Для подтверждения завершения процесса нажмите Enter, для отмены — Esc).

F10 — выход из программы
Функции для каждой клавиши могут изменяться, в зависимости от того, в каком меню программы вы находитесь, при этом доступные действия по соответствующим клавишам будут отображаться внизу окна, что упрощает работу с утилитой.
Команда id
Команда id используется для получения информации по текущему пользователю. В следующем примере, я попытался установить анализатор сетевого трафика Wireshark, на что система отреагировала сообщением, что я не могу выполнить данную команду, т.к. не имею прав суперпользователя (root)
После этого, чтобы проверить своего пользователя и группу, я выполнил команду и обратил внимание, что работал под учетной записью обычного пользователя diego в группе diego:
Для исправления ситуации необходимо произвести вход под учетной записью привилегированного пользователя (root) или прибегнуть к помощи команды .
Команда stat в Linux
Синтаксис команды очень простой. Ей надо передать опции и путь к файлу, для которого надо посмотреть информацию:
$ stat опции /путь/к/файлу
Опции передавать не обязательно и их совсем не много:
- -L, dereference — показывать информацию о файле вместо символической ссылки;
- -f, —file-system — показывать информацию о файловой системе в которой расположен файл;
- -c, —format — позволяет указать формат вывода вместо стандартного, каждый файл выводится с новой строки;
- —printf — аналогично —format, только для новой строки надо использовать \n;
- -t, —terse — показ информации в очень кратком виде, в одну строку;
- —version — показать версию утилиты.
Это все опции команды. Теперь давайте разберемся с примерами использования. Чтобы посмотреть информацию о файле достаточно запустить программу без опций передав ей путь к файлу, например /etc/passwd:
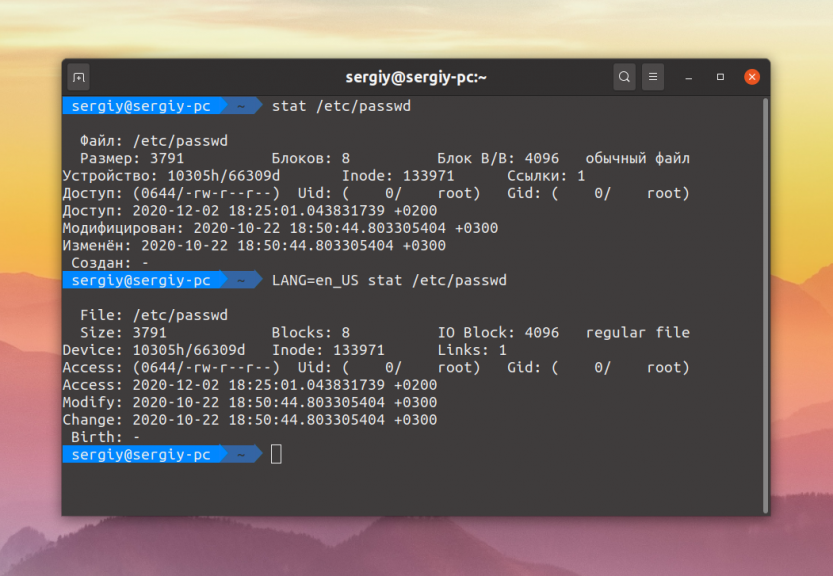
Рассмотрим что означает вывод программы:
- Файл (File) — путь к файлу по которому показывается информация;
- Размер (Size) — размер файла в байтах;
- Блок В/В (IO Block) — размер блока файловой системы в байтах;
- Блоков (Blocks) — количество блоков файловой системы, занятых файлом;
- Устройство (Device) — идентификатор устройства, например HDD, на котором сохранён файл;
- Inode — уникальный номер Inode этого файла;
- Ссылки (Links) — количество жестких ссылок на этот файл;
- Доступ (Access) — права доступа к файлу;
- Uid — идентификатор и имя пользователя-владельца файла;
- Gid — идентификатор и имя группы файла;
- Доступ (Access) — время последнего доступа к файлу;
- Модифицирован (Modify) — время когда в последний раз изменялся контент файла;
- Изменен (Change) — время, когда в последний раз изменялись атрибуты файла или контент файла;
- Создан (Birth) — зарезервировано для отображения первоначальной даты создания файла, но пока ещё не реализовано.
Надо ещё немного поговорить про формат времени. Например, время последнего доступа к файлу — 2020-12-02 18:25:01.043831739 +0200. Это время показывается с учётом временной зоны. А цифры +0200 показывают, что временная зона на компьютере, который создал или модифицировал этот файл на два часа больше чем UTC, то есть Europe/Kiev в зимнее время.
Если попробовать передать утилите символическую ссылку, то она покажет информацию только из Inode самой ссылки:
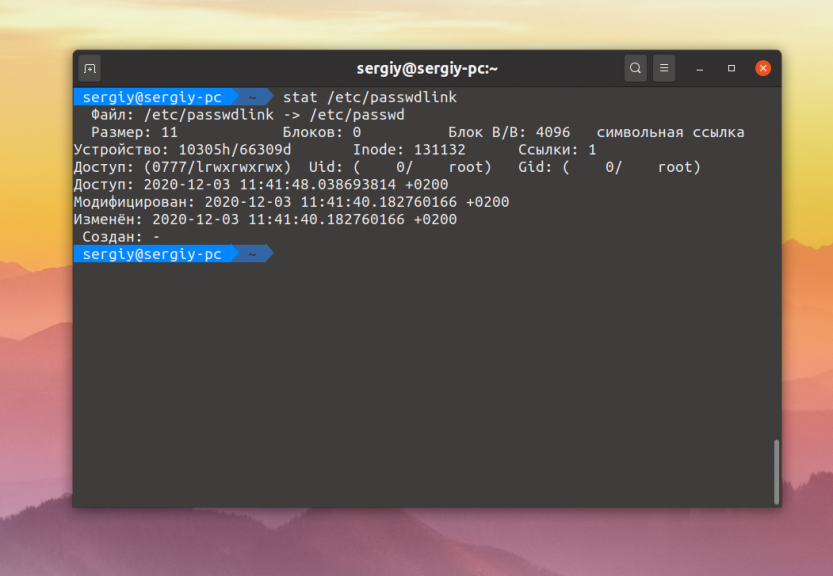
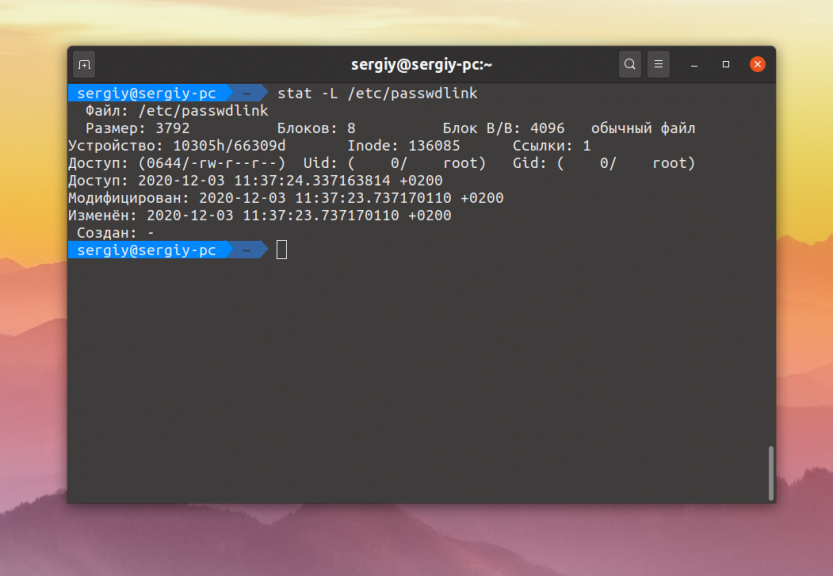
Для того чтобы увидеть информацию о файле, на который указывает ссылка надо использовать опцию -L:
Утилите можно передать не один файл, а несколько:
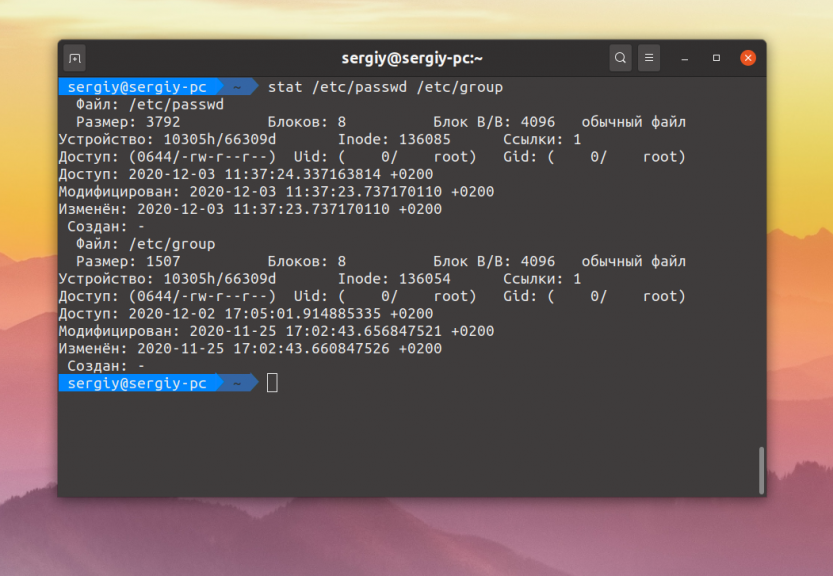
И тут уже понадобиться возможность настройки формата вывода. Для форматирования вывода можно использовать такие последовательности символов:
- %A — права доступа;
- %b — количество занятых блоков;
- %F — тип файла;
- %g — идентификатор группы файла;
- %G — имя группы файла;
- %i — идентификатор Inode;
- %n — имя файла;
- %s — размер файла;
- %u — идентификатор владельца файла;
- %U — имя владельца файла;
- %x — время последнего доступа;
- %y — время последней модификации контента;
- %z — время последнего изменения контента или атрибутов.
Это далеко не все возможные последовательности, больше вы моете найти в справке по утилите:
Например, давайте выведем только имя, файла, и время последней модификации его содержимоего:
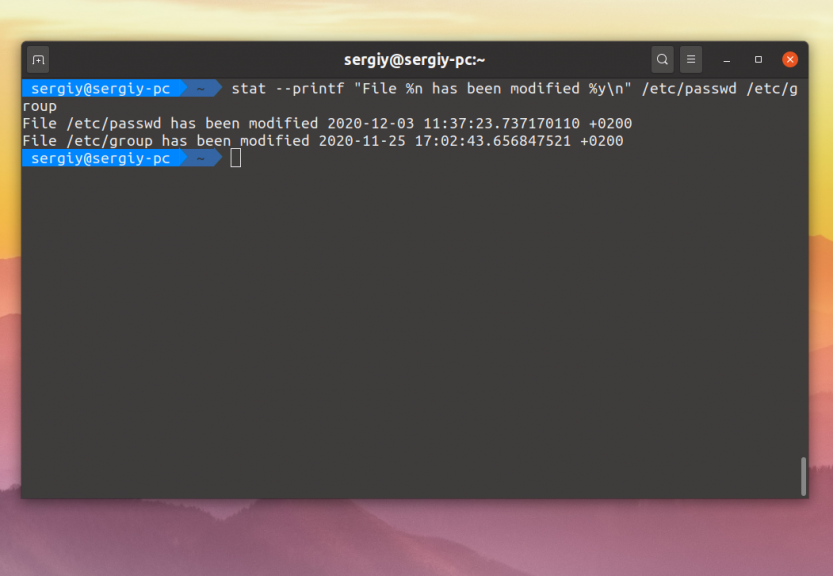
Если вы хотите посмотреть информацию о файловой системе, в которой расположен файл, то надо использовать опцию -f:
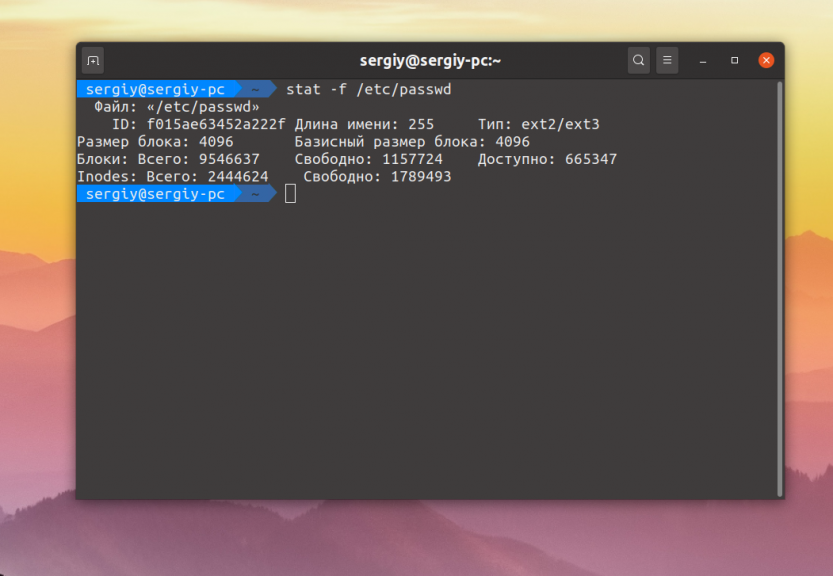
Давайте рассмотрим что означают поля, которые выводит утилита:
- Файл (File) — имя файла;
- Тип (Type) — тип файловой системы;
- ID — идентификатор файловой системы;
- Длина имени (Namelen) — максимальная длина имени в файловой системе;
- Размер блока (Block size) — объем данных при запросе на чтение или запись для оптимальной скорости работы;
- Базисный размер блока (Fundamental block size) — физический размер блока в файловой системе.
Дальше идут общее количество блоков в системе и количество свободных блоков.
atop
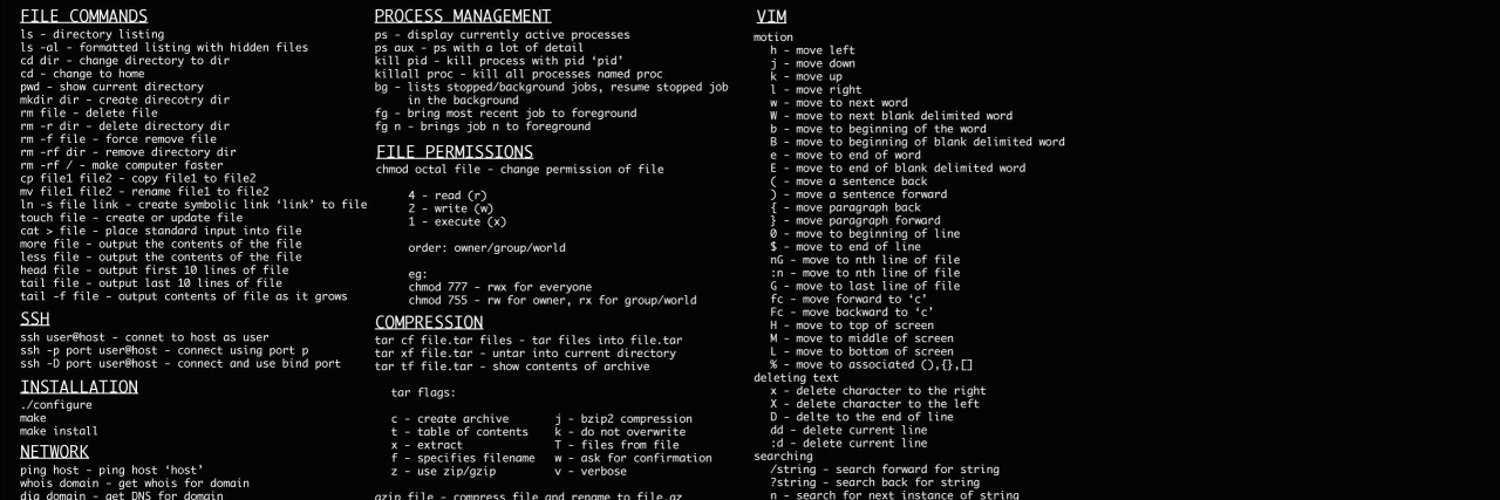
Основным преимуществом утилиты atop является функция ведения логов. Благодаря этому можно не только контролировать нагрузку в текущий момент, но и отслеживать работу процессов за прошедшие дни, чтобы диагностировать плавающие ошибки, которые сложно «поймать» при мониторинге в реальном времени.



Утилиту необходимо установить на сервер:
Ubuntu / Debian:
apt-get install atop -y
CentOS:
yum install atop -y
Также рекомендуем добавить atop в автозагрузку:
Ubuntu / Debian / CentOS 7:
systemctl enable atop
CentOS 6:
chkconfig atop on
Ubuntu 14.04:
rm /etc/init/atop.override
Запустите утилиту:
atop
Вывод выглядит примерно следующим образом:
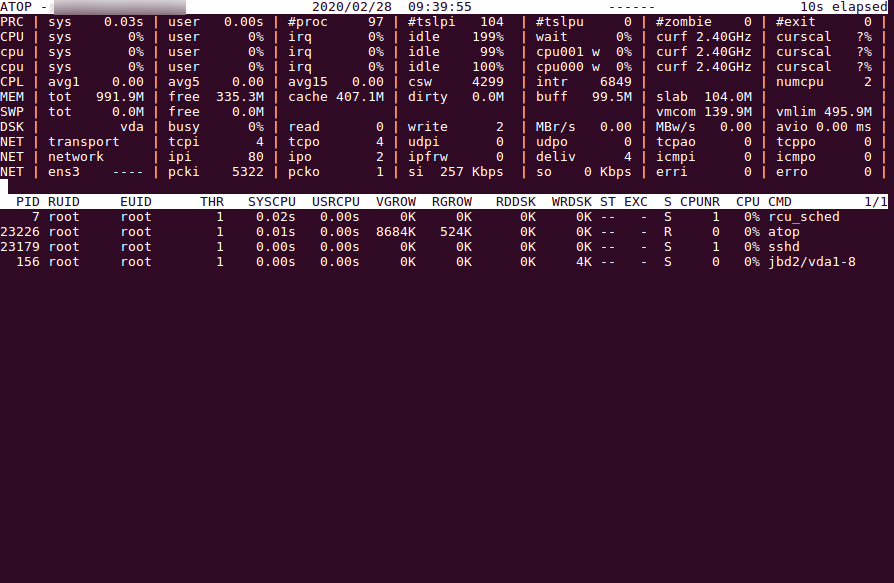
В верхней части отображается информация о системе и нагрузке на ключевые компоненты: процессор, ядра, память, сеть. Ниже выводится список процессов.
Для управления выводом можно использовать:
m — сортировка по используемой памяти
d — сортировка по нагрузке на диск
u — нагрузка по пользователям
v — подробная информация по процессам
i — изменение интервала обновления данных (по умолчанию 10 секунд)
g — вернуть вывод по умолчанию
n — сортировка процессов по нагрузке на сеть (доступна при наличии установленного патча ядра)
Сочетания клавиш с Shift выстроят текущий список процессов по соответствующим параметрам:
- Shift + m — сортировка процессов памяти
- Shift + с — сортировка по потреблению CPU (по умолчанию)
- Shift + d — сортировка по использованию диска
- Shift + n — сортировка по использованию сети
Логи atop
По умолчанию atop собирает сведения о состоянии системы каждые 10 минут и сохраняет их в файл лога, располагающийся в директории
Чтобы просмотреть лог за сегодня, выполните:
atop -r
Полезные клавиши:
- t — перейти вперед по времени
- Shift + t — перейти назад по времени
Файл за конкретный день имеет имя . Чтобы просмотреть лог за нужный день, используйте команду atop -r и укажите путь к файлу, например:
atop -r /var/log/atop/atop_20200227
Изменить настройки ведения лога можно в конфигурационном файле atop, который размещается по пути или — в CentOS.
# Интервал создания снимка нагрузки сервера, в секундах: INTERVAL=600 # Путь к директории с логами: LOGPATH="/var/log/atop" # Имя файла логов OUTFILE="$LOGPATH/daily.log"
Например, для того, чтобы atop делал снимок нагрузки раз в минуту, а не раз в 10 минут, укажите интервал 60.
После внесения изменений перезапустите atop:
systemctl restart atop.service
Перенаправление ввода/вывода
Практически все операционные системы обладают механизмом перенаправления ввода/вывода.
Linux не является исключением из этого правила. Обычно программы вводят текстовые данные с
консоли (терминала) и выводят данные на консоль. При вводе под консолью подразумевается клавиатура, а при выводе — дисплей терминала. Клавиатура и дисплей — это, соответственно, стандартный ввод и вывод (stdin и stdout). Любой ввод/вывод можно интерпретировать как ввод из некоторого файла и вывод в файл. Работа с файлами производится через их дескрипторы. Для организации ввода/вывода в UNIX используются три файла: stdin (дескриптор 1), stdout (2) и stderr(3).


![Top, htop, atop интерактивные просмоторщики процессов [айти бубен]](https://smartshop124.ru/wp-content/uploads/7/e/e/7ee9ad84807d7b077c698db3f8bc924f.jpeg)

Символ > используется для перенаправления стандартного вывода в файл.
Пример:
$ cat > newfile.txt
Стандартный ввод команды cat будет перенаправлен в файл newfile.txt, который будет создан после выполнения этой команды. Если файл с этим именем уже существует, то он будет перезаписан. Нажатие Ctrl + D остановит перенаправление и прерывает выполнение команды cat.
Символ < используется для переназначения стандартного ввода команды. Например, при выполнении команды cat Символ >> используется для присоединения данных в конец файла (append) стандартного вывода команды. Например, в отличие от случая с символом >, выполнение команды cat >> newfile.txt не перезапишет файл в случае его существования, а добавит данные в его конец.
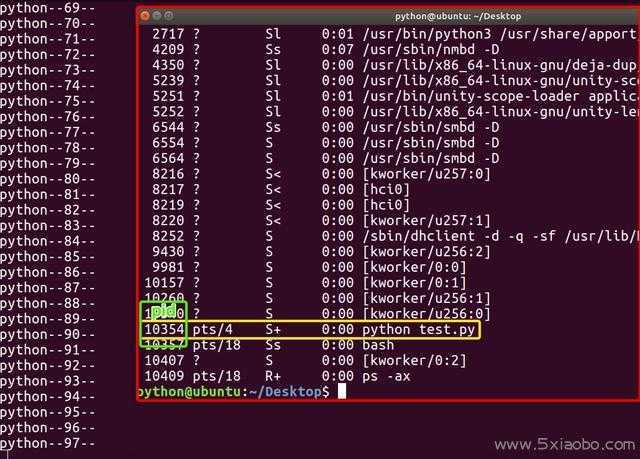
Символ | используется для перенаправления стандартного вывода одной программы на стандартный ввод другой. Напрмер, ps -ax | grep httpd.



