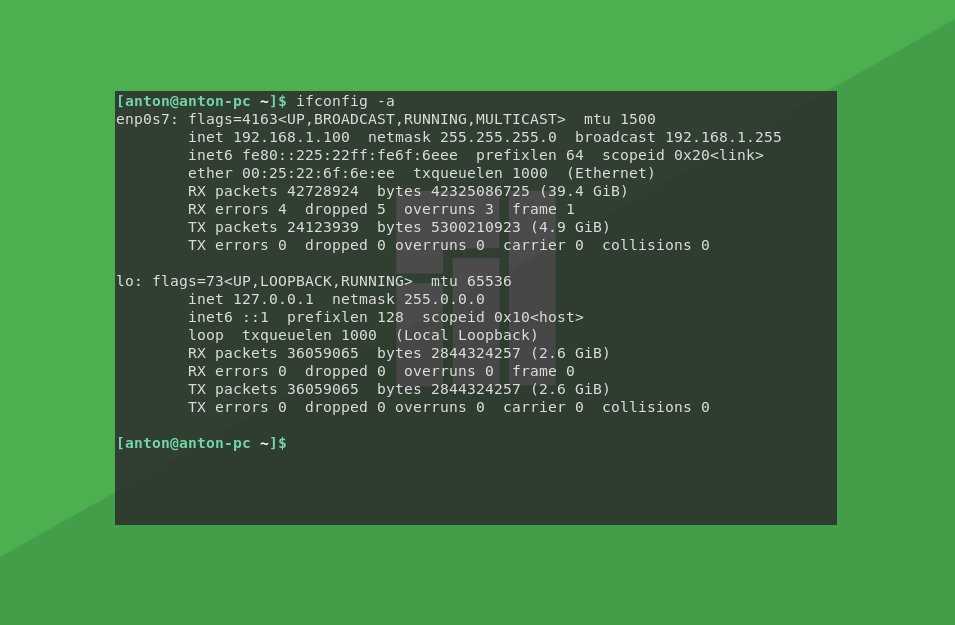
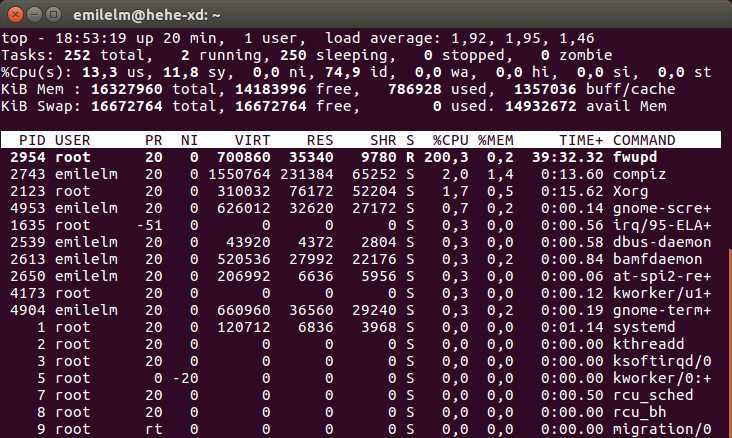
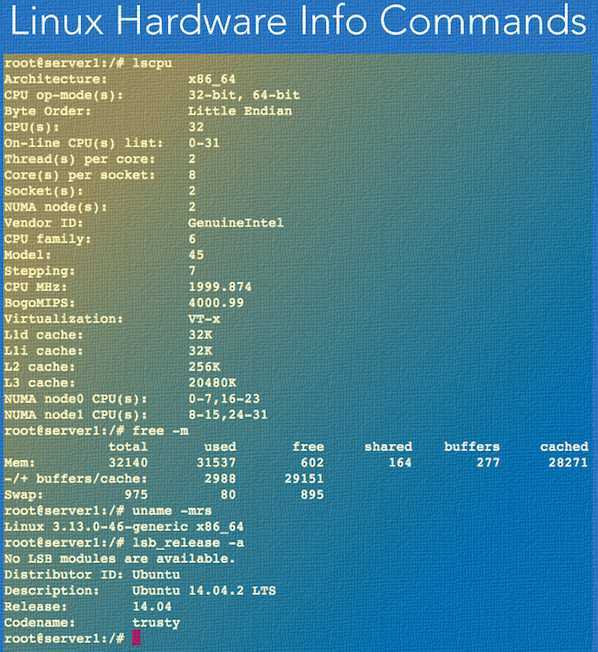
Метод 1 — проверьте информацию о процессоре с помощью lscpu
Утилита командной строки lscpu, собирает информацию архитектуры CPU от sysfs и архитектуры конкретных библиотек, как /proc/cpuinfo. Команда собирает сведения о ЦП, такие как количество ЦП, потоков, ядер, сокетов и узлов с неоднородным доступом к памяти (NUMA). Он также получает информацию о кэшах ЦП и совместном использовании кеша, семействе, модели, bogoMIPS, порядке байтов, пошаговом режиме и т.д. Команда lscpu является частью пакета util-linux, поэтому не беспокойтесь об установке.
Чтобы найти информацию о процессоре в Linux с помощью команды lscpu, просто запустите ее без каких-либо параметров:
$ lscpu
Пример вывода:
Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian Address sizes: 36 bits physical, 48 bits virtual CPU(s): 4 On-line CPU(s) list: 0-3 Thread(s) per core: 2 Core(s) per socket: 2 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 42 Model name: Intel(R) Core(TM) i3-2350M CPU @ 2.30GHz Stepping: 7 CPU MHz: 838.397 CPU max MHz: 2300.0000 CPU min MHz: 800.0000 BogoMIPS: 4589.90 Virtualization: VT-x L1d cache: 64 KiB L1i cache: 64 KiB L2 cache: 512 KiB L3 cache: 3 MiB NUMA node0 CPU(s): 0-3
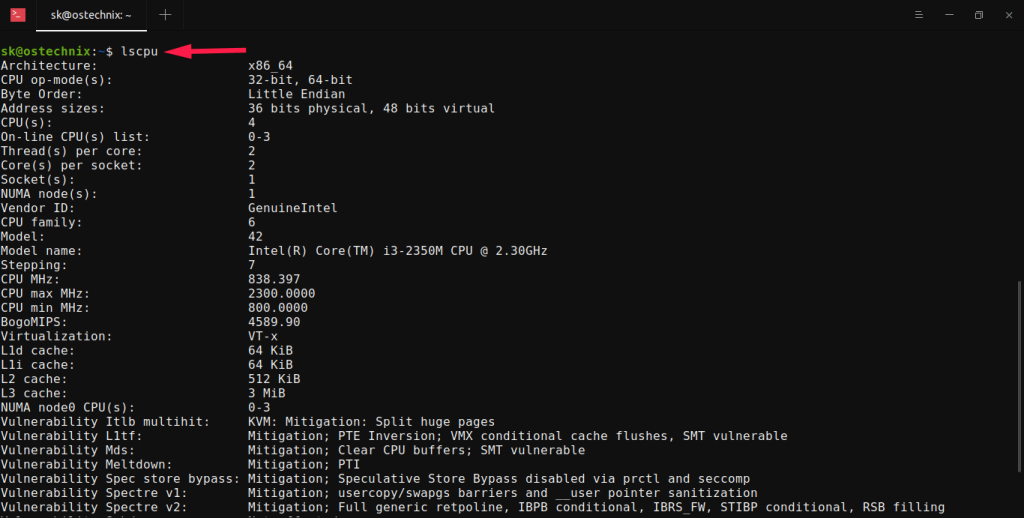
1.1. Отображение конкретной информации о процессоре, используемой lscpu в Linux
Как видите, lscpu отображает полную информацию о вашем процессоре. Вы также можете сузить результаты, используя команду для фильтрации определенной детали, например названия модели , как показано ниже:
$ lscpu | grep -i 'Model name' Model name: Intel(R) Core(TM) i3-2350M CPU @ 2.30GHz
Если вы хотите отобразить только модель процессора, запустите:
$ lscpu | grep -i "Model name:" | cut -d':' -f2- - Intel(R) Core(TM) i3-2350M CPU @ 2.30GHz
Точно так же вы можете найти другие сведения о ЦП, например количество ядер ЦП , как показано ниже:
$ lscpu | grep -i "CPU(s)" CPU(s): 4 On-line CPU(s) list: 0-3 NUMA node0 CPU(s): 0-3
1.2. Найдите поколение процессоров в Linux
Вы обратили внимание на числа (например, 2350M) после части «i3-» в приведенных выше выходных данных? Первые 2 после i3 показывают поколение процессора. В данном случае мой процессор 2-го поколения
Чтобы узнать больше о номерах процессоров Intel, перейдите по этой ссылке .
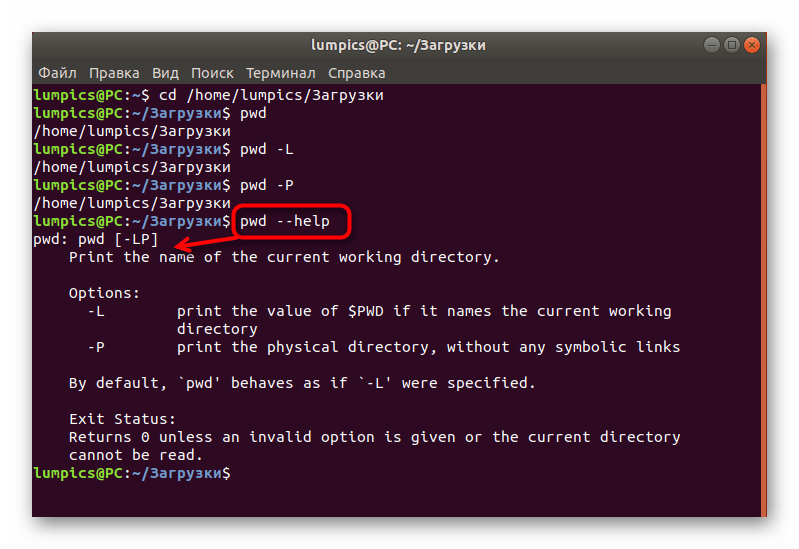
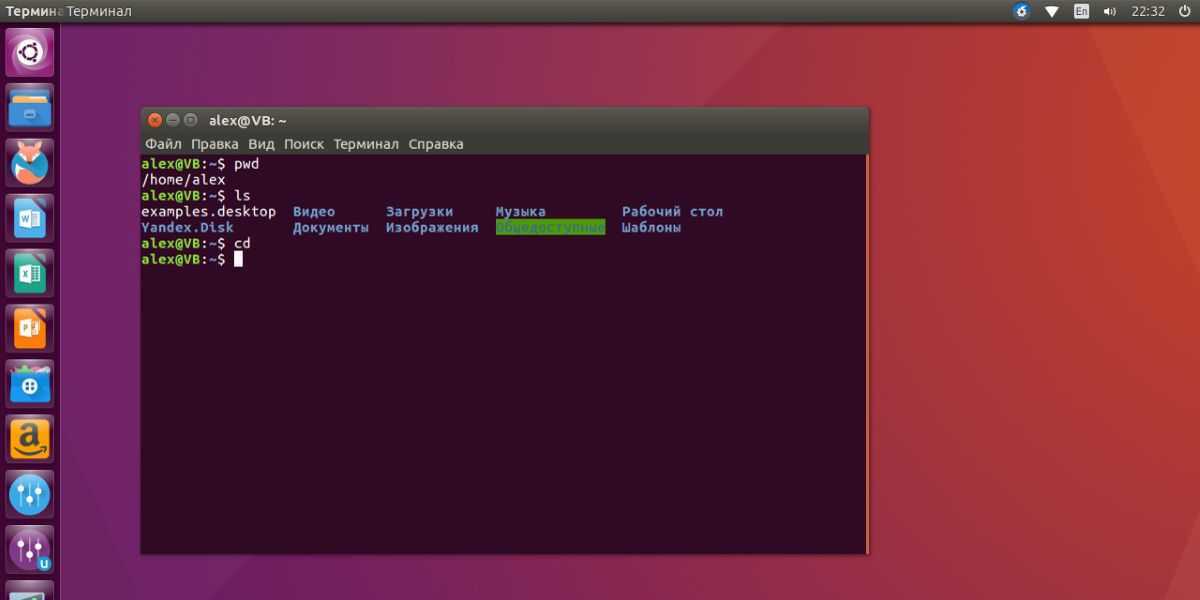
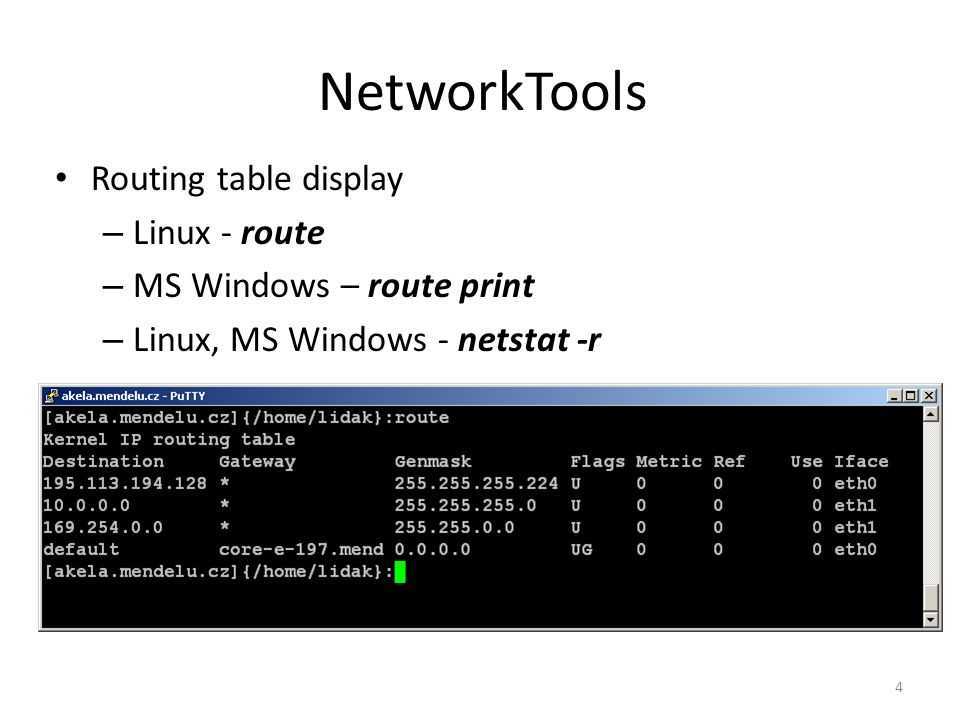
Применяем команду PWD в Linux
Давайте начнем с областей применения команды PWD. Конечно, в первую очередь на ум приходит задача определения пути текущего каталога, который в будущем может быть использован для сохранения различных файлов или применяться при других обстоятельствах. Дополнительно значение этой утилиты присваивают в переменные или добавляют данную команду в скрипты, о чем тоже упомянем далее. Сперва представим самый простой пример использования PWD, а затем уже затронем дополнительные опции.
Активация PWD в консоли
Синтаксис PWD крайне прост, поскольку включает эта утилита только две опции. Их мы рассмотрим позже, а сейчас давайте разберем стандартную ситуацию в небольшом пошаговом примере.
- Запустите «Терминал» удобным для вас образом, например, через значок в меню приложений.

Далее перейдите по необходимому пути или выполняйте абсолютно любые действия. Мы специально выбрали расположение, чтобы далее показать, как PWD выведет его в новой строке. Задействуем для этого команду cd.
Теперь достаточно просто прописать . Для этого даже не обязательно использовать sudo, поскольку данная команда не зависит от прав суперпользователя.
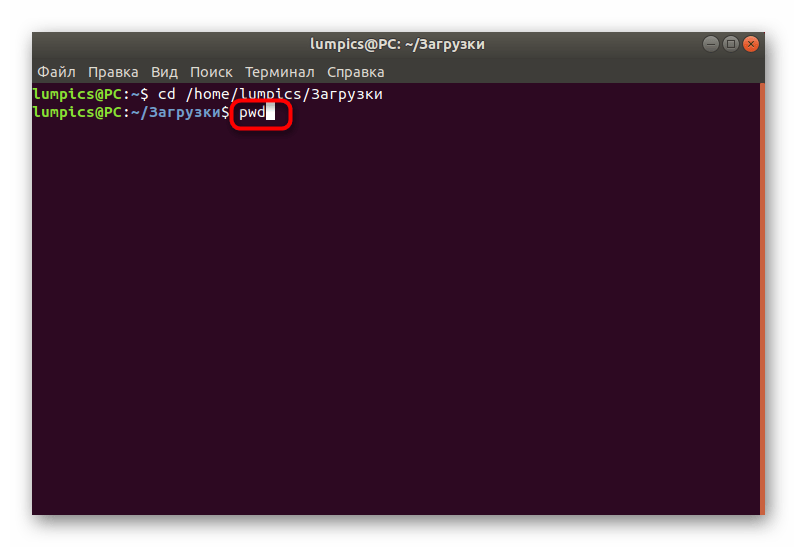
На экране в новой строке сразу же отобразится полный путь к текущему расположению.
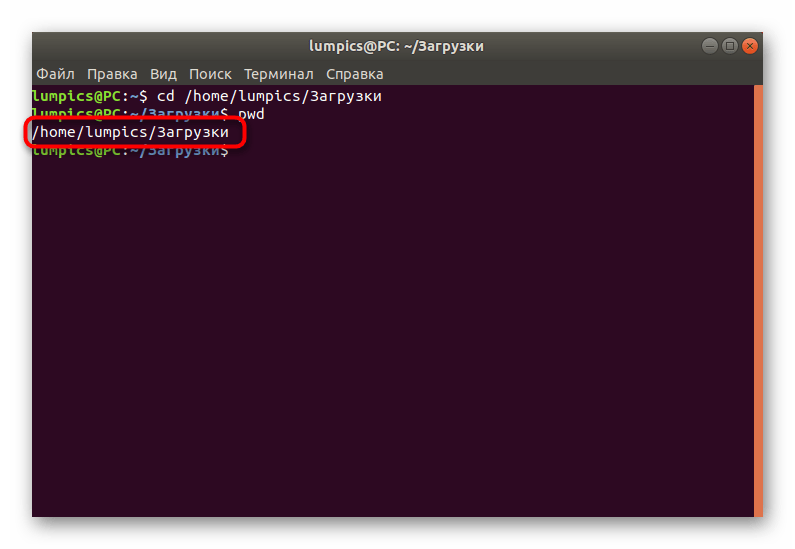
Как видите, определяется расположение через PWD буквально за несколько секунд, при этом нет никаких ограничений по текущей активной директории: это может быть даже сетевая папка.
Использование опций
Как уже было сказано выше, в PWD присутствуют всего две доступные опции, которые можно применить при выполнении команды.
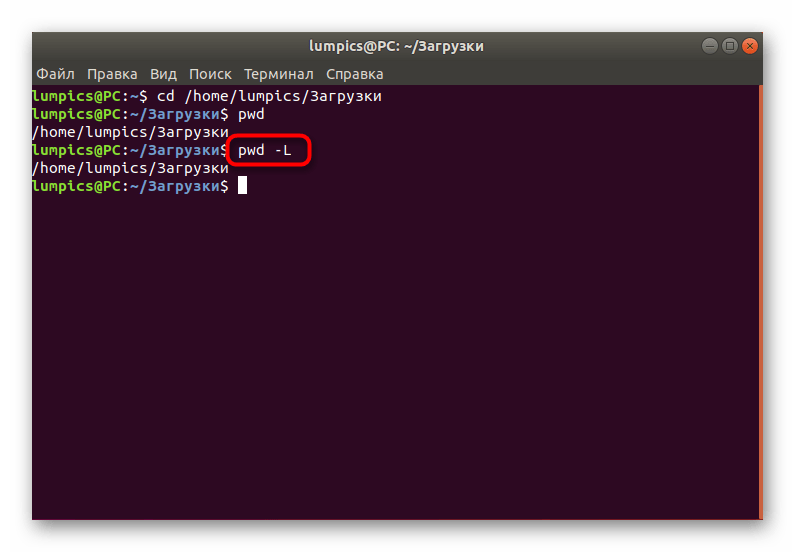
- Если вы введете , то в новой строке отобразится результат без преобразования символических ссылок.
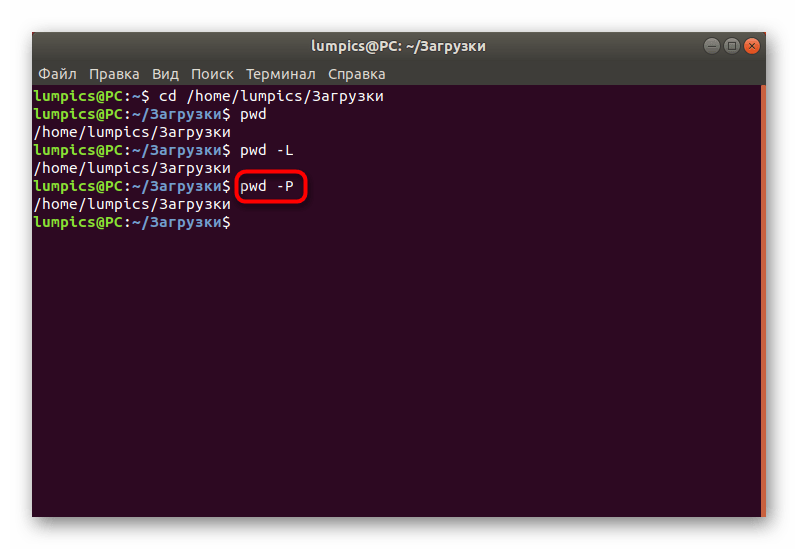
, наоборот, все символические ссылки преобразует в исходные имена директорий, где они были указаны.
Введите , чтобы отобразить официальную документацию. В ней вы можете узнать, как описали опции сами разработчики.
Выше мы специально не стали объяснять, что такое символические ссылки, поскольку этой теме посвящена отдельная статья на нашем сайте. В ней рассказывается о команде ln, которая напрямую связана с жесткими и символическими ссылками, поэтому советуем изучить ее, чтобы узнать больше информации по этой теме.

Подробнее: Команда ln в Linux
Дополнительные действия с PWD
Команда PWD может быть связана с созданием или просмотром скриптов, а также ее можно записать в переменную. Все это относится к дополнительным действиям, которые мы тоже затронем в рамках данного материала.
- Если ваше расположение относится к скрипту, используйте переменную окружения через , чтобы узнать текущий путь.
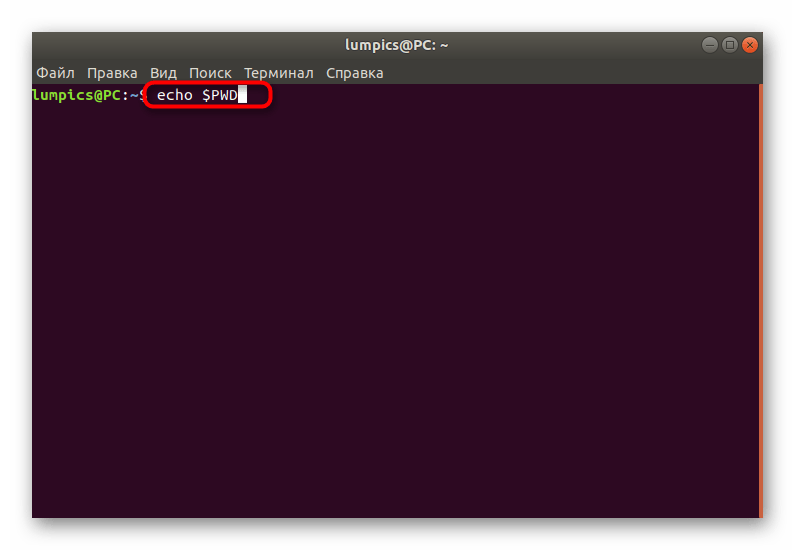
При необходимости создания переменной с записью текущего расположения введите , где CWD — имя переменной. Эту же команду используйте и при создании пользовательских скриптов, ее вид может быть представлен и в варианте .
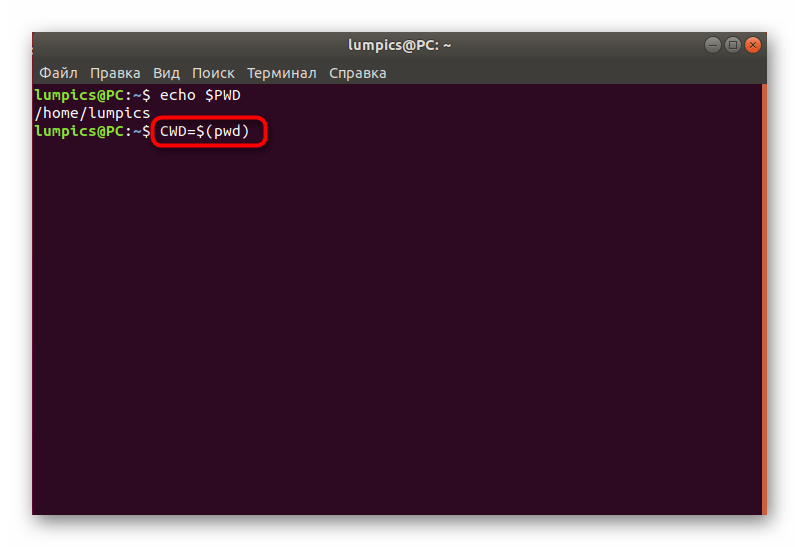
Теперь вы можете вызвать переменную через , активировав команду нажатием на Enter.
Результат будет такой же, как и при стандартном использовании рассматриваемой утилиты.
Это все, что мы хотели рассказать о стандартной утилите операционных систем Linux под названием PWD. Как видите, это узконаправленная команда, позволяющая определить только один параметр, однако она находит свое применение в самых разных ситуациях.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
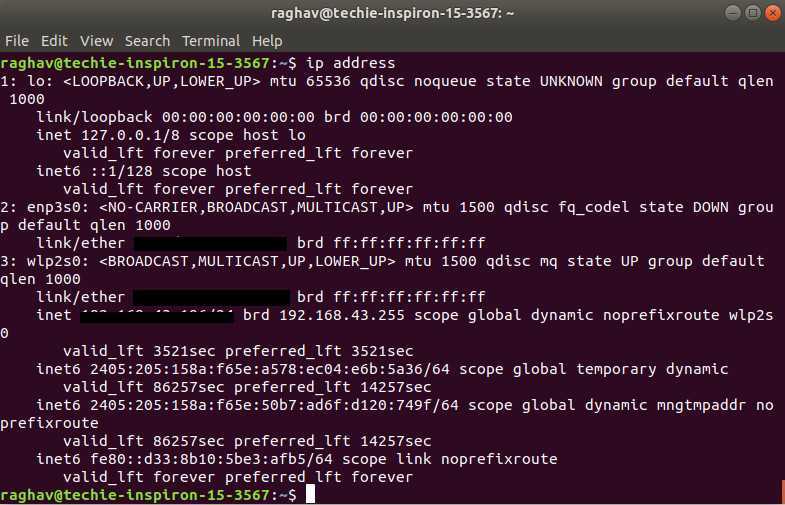
Операционная система, имя хоста и ядро Linux
Опция -o или —operating-system отображает используемую операционную систему:
![]()
Скриншот №2. Опция operating-system
Опция -n или —nodename отображает имя хоста:
![]()
Скриншот №3. Опция nodename
Чтобы найти релиз ядра Linux, используйте параметр -r или —kernel-release:
Скриншот №4. Параметр kernel-release
Опция -v или —kernel-version выводит версию ядра:
![]()
Скриншот №5. Опция kernel-version
Если вам нужна вся вышеуказанная информация в одной команде, используйте параметр -a или —all следующим образом:
![]()
Скриншот №6. Параметр all
Наконец, чтобы узнать версию утилиты uname, используйте команду —version:

Скриншот №7. Команда version
Как узнать pid процесса Linux
1. ps
Самый распространённый способ узнать PID Linux — использовать утилиту ps:
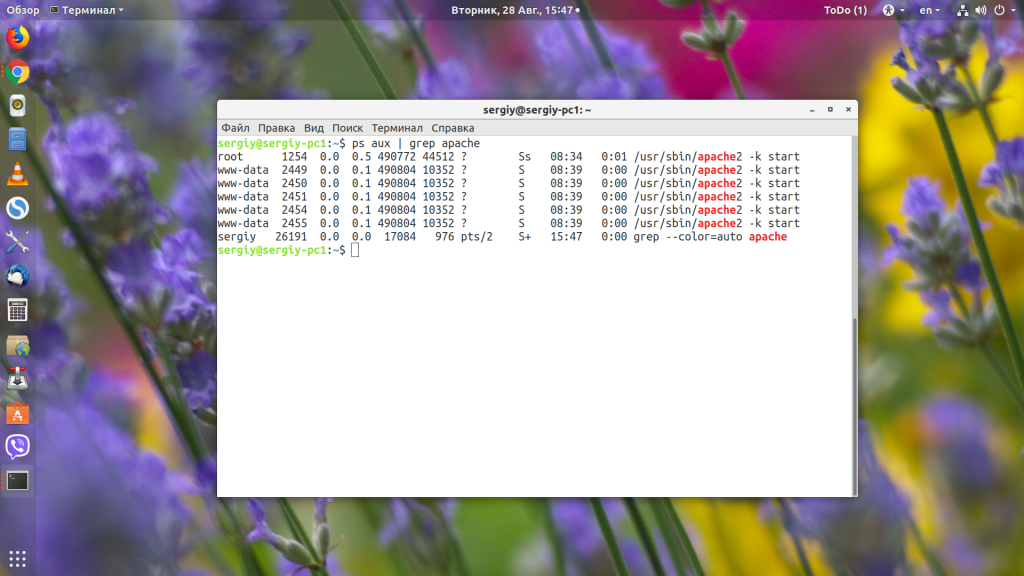
Кроме нужного нам процесса, утилита также выведет PID для grep, ведь процесс был запущен во время поиска. Чтобы его убрать, добавляем такой фильтр:
Например, узнаём PID всех процессов, имя которых содержит слово «Apache»:
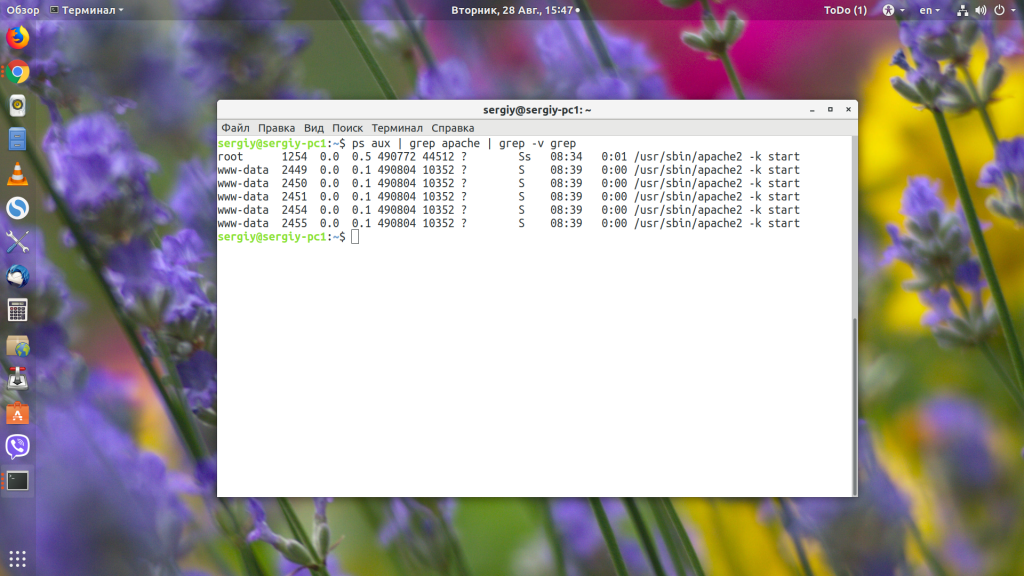
2. pgrep
Если вам не нужно видеть подробную информацию о процессе, а достаточно только PID, то можно использовать утилиту pgrep:
По умолчанию утилита ищет по командной строке запуска процесса, если нужно искать только по имени процесса, то надо указать опцию -f:
3. pidof
Эта утилита ищет PID конкретного процесса по его имени. Никаких вхождений, имя процесса должно только совпадать с искомым:
С помощью опции -s можно попросить утилиту выводить только один PID:
4. pstree
Утилита pstree позволяет посмотреть список дочерних процессов для определённого процесса, также их pid-идентификаторы. Например, посмотрим дерево процессов Apache:
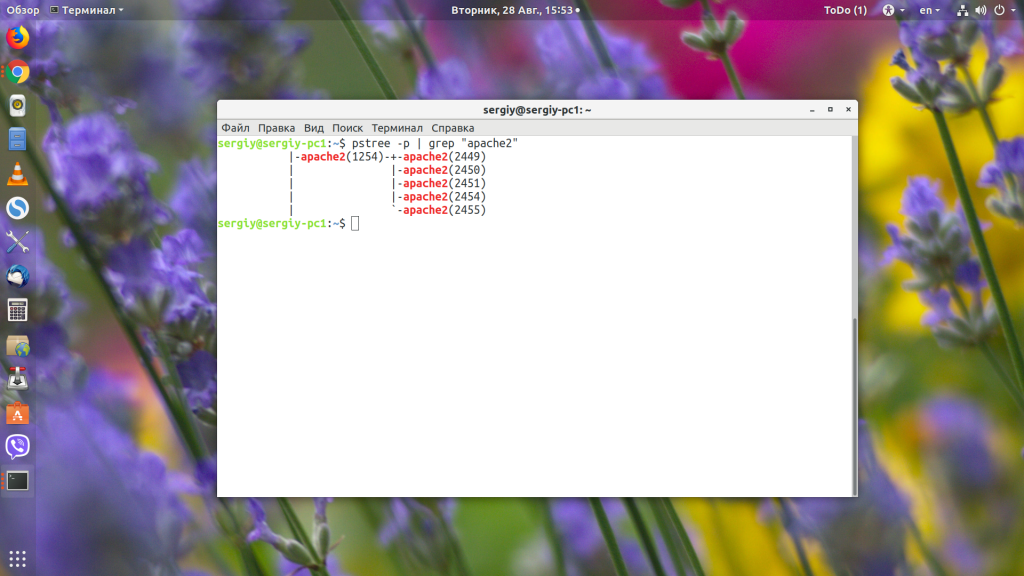
Как узнать PID скрипта
Когда вы запускаете скрипт в оболочке, например Bash запускается процесс известный как подоболочка и выполняет последовательно все команды скрипта. Чтобы узнать PID процесса подоболочки Bash, запущенной для скрипта, обратитесь к специальной переменной $$. Эта переменная доступна только для чтения, поэтому вы не сможете ее редактировать:
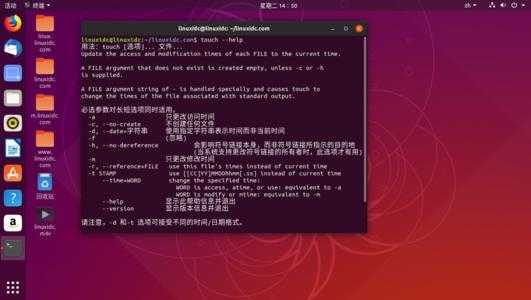
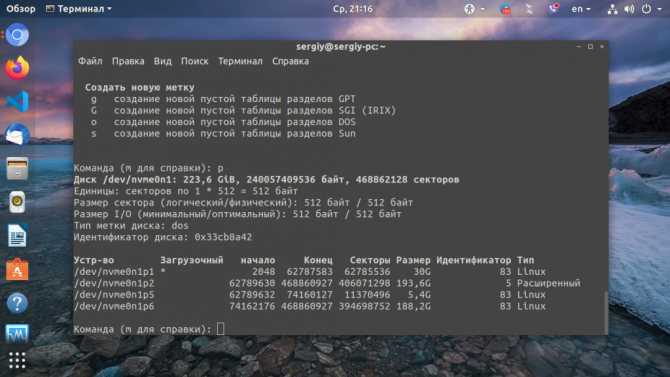
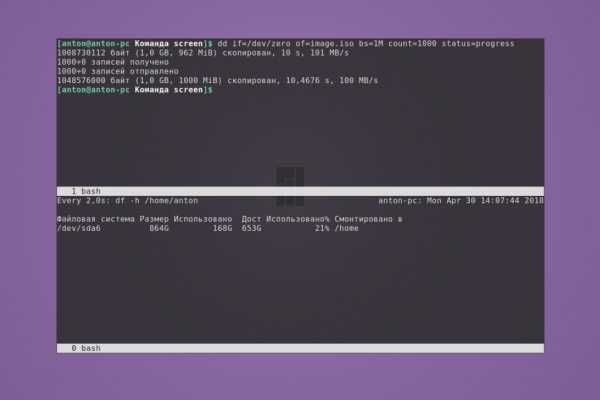
Метод 4 — получить сведения о процессоре с помощью dmidecode
Утилита dmidecode извлекает информацию о аппаратных компонентов системы от таблицы DMI (Desktop Management Interface). Сначала он попытается прочитать таблицу DMI из sysfs, а затем попытается прочитать непосредственно из памяти, если доступ sysfs не удался. После нахождения таблицы DMI dmidecode проанализирует эту таблицу и отобразит информацию об оборудовании системы в удобочитаемом формате. Dmidecode предустановлен в большинстве операционных систем Linux, поэтому не будем беспокоиться об установке.
Чтобы получить информацию о процессоре с помощью dmidecode в Linux, запустите:
$ sudo dmidecode --type processor
Пример вывода:

Сложный выбор дистрибутива
Дистрибутивов Linux очень много. Есть базовые, есть основанные на базовых, есть основанные на основанных, есть… Их действительно очень и очень много. Причем многие из них очень разные и имеют свои специфические особенности.
С одной стороны хорошо, когда есть выбор. Но, к сожалению, есть много дистрибутивов, которые отличаются от базовых только слегка измененной темой оформления, набором обоев рабочего стола, составом предустановленных программ, и, возможно, парой утилит, которые специально были написаны для данного дистрибутива, но на большее разработчиков уже не хватило.
Такие дистрибутивы тоже нужны, иногда они даже удобнее и красивее, чем базовый дистрибутив, но многие из них абсолютно не представляют интереса, а это портит общую картину и мешает репутации Linux.
Разнообразие дистрибутивов вызывает дополнительные сложности при подготовке пакетов программного обеспечения под Linux. Под определенные семейства дистрибутивов необходимо готовить определенные установочные пакеты.
И еще один факт. Многообразие дистрибутивов может поставить новичка в Linux в сложное положение. Вместо того, чтобы взять и скачать, например, один единый дистрибутив Linux (которого не существует), новичку придется сначала выяснить, чем отличаются дистрибутивы друг от друга и решить какой ему использовать. А если вдруг ему не понравится установленная система, то нужно начинать новый поиск. С Windows таких проблем не возникает.
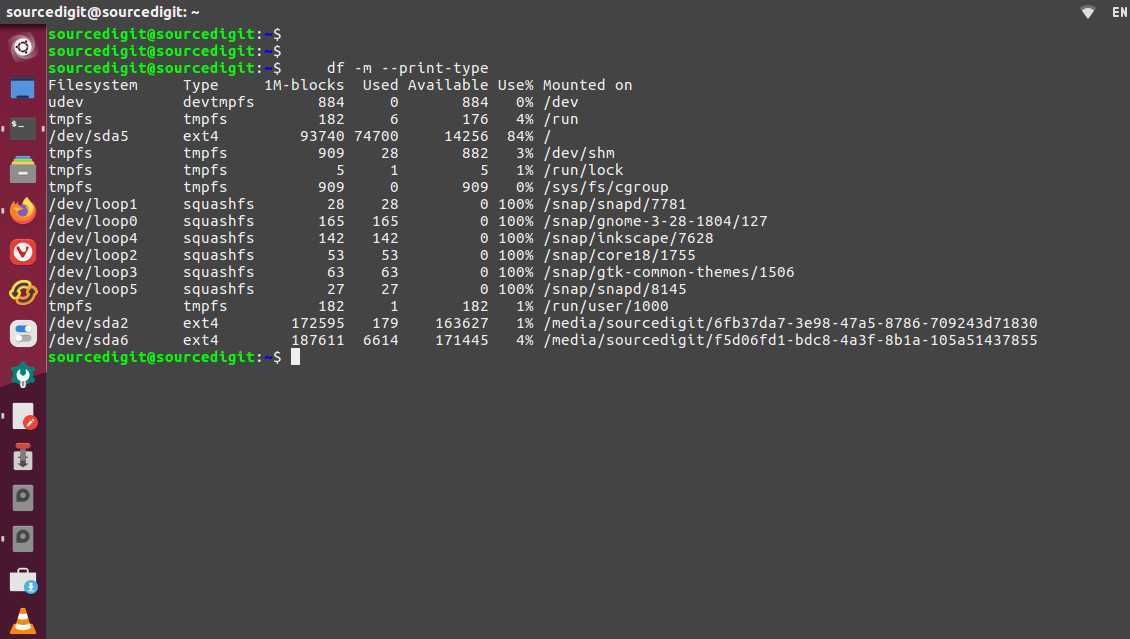
Структура fstab
Каждая строка содержит настройки, необходимые для установки одного раздела, диска или сетевого ресурса.Строка имеет шесть столбцов, разделенных пробелами или символами табуляции.
Поле , указывает на физическое место размещения файловой системы, по которому определяется конкретный раздел или устройство хранения для монтирования.
Конкретное место расположения файловой системы может быть определено различными способами. В файле можно указать имя файла устройства, его метку (Label) или UUID. Например для UUID:
</etc/fstab>
# <file system> <dir> <type> <options> <dump> <pass>
UUID="339df6e7-91a8-4cf9-a43f-7f7b3db533c6" / ext4 defaults 0 1
Или для меток(Label):
</etc/fstab>
# <file system> <dir> <type> <options> <dump> <pass>
LABEL="Gentoo" / ext4 defaults 0 1
- Поле , определяет путь, по которому будет смонтирована , точка монтирования.
- Поле <type>, тип файловой системы. Поддерживается множество типов: ext2, ext3, ext4, btrfs, ReiserFS, XFS, JFS, smbfs, iso9660, vfat, NTFS, swap и auto. При выборе команда попытается определить реальный тип файловой системы самостоятельно.
- Поле , параметры монтирования файловой системы, в том числе если файловая система должна быть установлена при загрузке.
Если используются все значения по умолчанию, то используется специальный ключ . Если хоть одна опция задана явно, то defaults указывать не нужно ( служит только для того, что была занята позиция в строке). Для полного списка опций используйте команду .
| auto | Файловая система монтируется при загрузке автоматически или после выполнения команды ‘mount -a’. |
| noauto | Файловая система может быть смонтирована только вручную. |
| exec | Позволяет исполнять бинарные файлы на разделе диска. Установлено по умолчанию. |
| noexec | Бинарные файлы не выполняются. Использование опции на корневой системе приведёт к её неработоспособности. |
| ro | Монтирует файловую систему только для чтения. |
| rw | Монтирует файловую систему для чтения/записи. |
| sync | Все операции ввода-вывода должны выполняться синхронно. |
| async | Все операции ввода-вывода должны выполняться асинхронно. |
| user | Разрешает любому пользователю монтировать файловую систему. Применяет опции noexec, nosuid, nodev, если они не переопределены. |
| nouser | Только суперпользователь может монтировать файловую систему. Используется по умолчанию. |
| defaults | Использовать значения по умолчанию. Соответствует набору rw, suid, dev, exec, auto, nouser, async. |
| suid | Разрешить операции с suid и sgid битами. В основном используются, чтобы позволить пользователям выполнять бинарные файлы со временно приобретёнными привилегиями для выполнения определённой задачи. |
| nosuid | Запрещает операции с suid и sgid битами. |
| nodev | Данная опция предполагает, что на монтируемой файловой системе не будут созданы файлы устройств (/dev). Корневой каталог и целевая директория команды chroot всегда должны монтироваться с опцией dev или defaults. |
| atime | Включает запись информации о последнем времени доступа (atime) при каждом чтении файла. Включено по умолчанию на Linux до v.2.6.29 включительно. |
| noatime | Отключает запись информации о последнем времени доступа (atime) при каждом чтении файла. |
| relatime | Включает запись информации о последнем времени доступа при чтении файла, если предыдущее время доступа (atime) меньше времени изменения файла (ctime). Включено по умолчанию на Linux начиная с v.2.6.30. |
| notail | Отключает «упаковку хвостов файлов». Опция работает только с файловой системой ReiserFS. |
Стоит обратить внимание на тот факт, что могут быть составлены из нескольких значений разделенных запятой.
- Поле <dump>, используется утилитой dump для определения того, нужно ли создать резервную копию(провести архивацию) данных в файловой системе. Возможные значения: 0 или 1. Если указано число 1, dump создаст резервную копию, если указано число 0 то функция отключается.
- Поле <pass>, используется программой fsck для определения того, нужно ли проверять целостность файловой системы. Возможные значения: 0, 1 или 2. Значение 1 следует указывать только для корневой файловой системы (с точкой монтирования /); для остальных ФС, которые вы хотите проверять, используйте значение 2, которое имеет менее высокий приоритет.В файловых системах, для которых в поле указано значение 0, будет отключена проверка целостности для этого раздела в целом.
Ограничение процессов
Управление процессами в Linux позволяет контролировать практически все. Вы уже видели что можно сделать, но можно еще больше. С помощью команды ulimit и конфигурационного файла /etc/security/limits.conf вы можете ограничить процессам доступ к системным ресурсам, таким как память, файлы и процессор. Например, вы можете ограничить память процесса Linux, количество файлов и т д.
Запись в файле имеет следующий вид:
<домен> <тип> <элемент> <значение>
- домен — имя пользователя, группы или UID
- тип — вид ограничений — soft или hard
- элемент — ресурс который будет ограничен
- значение — необходимый предел
Жесткие ограничения устанавливаются суперпользователем и не могут быть изменены обычными пользователями. Мягкие, soft ограничения могут меняться пользователями с помощью команды ulimit.

Рассмотрим основные ограничения, которые можно применить к процессам:
- nofile — максимальное количество открытых файлов
- as — максимальное количество оперативной памяти
- stack — максимальный размер стека
- cpu — максимальное процессорное время
- nproc — максимальное количество ядер процессора
- locks — количество заблокированных файлов
- nice — максимальный приоритет процесса
Например, ограничим процессорное время для процессов пользователя sergiy:
Посмотреть ограничения для определенного процесса вы можете в папке proc:
Ограничения, измененные, таким образом вступят в силу после перезагрузки. Но мы можем и устанавливать ограничения для текущего командного интерпретатора и создаваемых им процессов с помощью команды ulimit.
Вот опции команды:
- -S — мягкое ограничение
- -H — жесткое ограничение
- -a — вывести всю информацию
- -f — максимальный размер создаваемых файлов
- -n — максимальное количество открытых файлов
- -s — максимальный размер стека
- -t — максимальное количество процессорного времени
- -u — максимальное количество запущенных процессов
- -v — максимальный объем виртуальной памяти
Например, мы можем установить новое ограничение для количества открываемых файлов:
Теперь смотрим:
Установим лимит оперативной памяти:
Напоминаю, что это ограничение будет актуально для всех программ, выполняемых в этом терминале.
Параметры fsck
Существует список опций (параметров), которые доступны с помощью утилиты fsck. Все они используются для конкретных целей. Вот некоторые полезные опций fsck:
1. Perform fsck dry run — это выполнение тестового запуска.
2. Опция -y на все вопросы автоматически ответит ДА, это позволит избежать всех подсказок
3. Параметр -n выведите ошибку fsck без ремонта
4. Запуск fsck во всех файловых системах
5. Запуск fsck для определенной файловой системы
Команда fsck является оболочкой и внутренне использует соответствующую команду проверки файловой системы (). Вы можете найти следующие различные команды проверки fsck, такие как fsck.ext2, fsck.ext3, fsck.ext4 и т.д.).
В следующей таблице показаны все параметры (опции) команды fsck.
Параметры fsck
| Вариант | Описание |
| -A | Проверяет все файловые системы, присутствующие в файле /etc/fstab |
| -C | Отображает индикатор выполнения |
| -f | Принудительно проверяет файловую систему |
| -l | Блокирует устройство |
| -M | Не проверяет смонтированные файловые системы |
| -N | Выводит на печать без выполнения каких — либо действий |
| -P | Параллельная проверка нескольких файловых систем |
| -p | Автоматически устранять любые проблемы, которые могут быть безопасно устранены без необходимости взаимодействия с пользователем |
| -R | Не проверяет корневую файловую систему при использовании с -A |
| -r | Отображает статистику для каждого проверенного устройства |
| -T | Не показывает название |
| -t | Укажите типы файловых систем, которые необходимо проверить (это можно сделать с помощью команды ) |
| -v | Предоставляет подробную информацию |
| -y | Отвечает «да» на все вопросы |
fstab — это файл, который указывает операционной системе, как и где монтировать разделы. Вы так же можете найти список записей в файле fstab /etc/fstab.
Параметр <pass> определяет порядок, в котором выполняются проверки файловых системы во время перезагрузки. Если значение равно 0, то оно не проверяется. Если значение равно 1, файловые системы проверяются по одной за раз. А если значение равно 2, поиск во всех файловых системах выполняется одновременно. Значение корневой файловой системы равно 1, а все остальные файловые системы, которые вы хотите проверить, должны иметь значение 2.
Образец файла /etc/fstab:

Проверка файловой системы командой Fsck в Linux
Ограничение пользователей
и позволяют контролировать, какие пользователи могут создавать задания с помощью команды или . Файлы состоят из списка имен пользователей, по одному имени пользователя в строке.
По умолчанию существует только файл и он пуст, что означает, что все пользователи могут использовать команду . Если вы хотите отказать в разрешении определенному пользователю, добавьте имя пользователя в этот файл.
Если файл существует, только пользователи, перечисленные в этом файле, могут использовать команду .
Если ни один из файлов не существует, только пользователи с правами администратора могут использовать команду .
Способ второй — создание туннеля
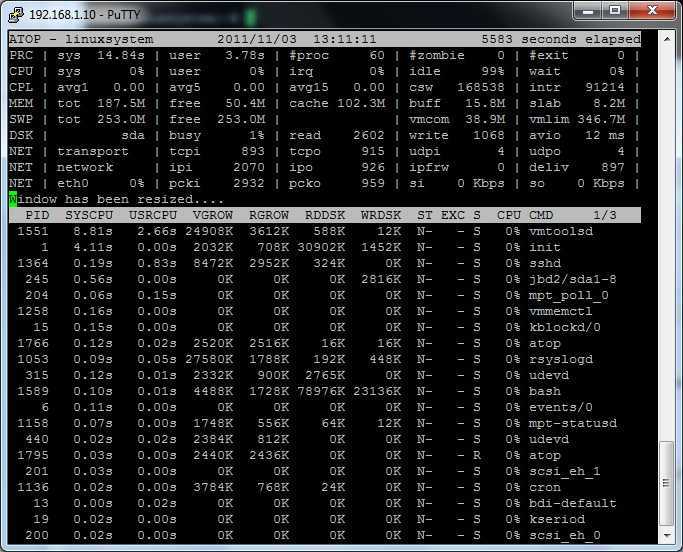
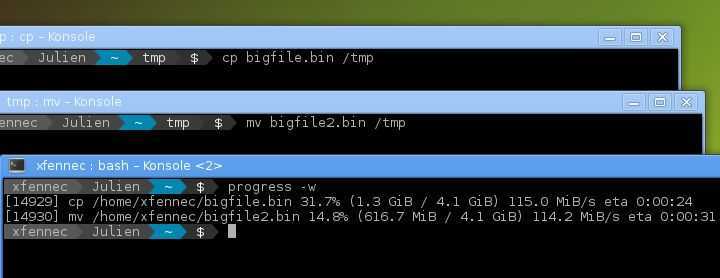
То, что мы рассмотрели выше — не единственный способ посмотреть прогресс команды linux. Еще есть утилита pv. Она намного проще и выполняет только одну задачу — считает все данные проходящие через нее. Может читать поток из файла или стандартного ввода.
Поэтому ее можно использовать чтобы посмотреть прогресс выполнения команды в Linux. Например, создадим такой туннель для dd:
# dd if=/dev/zero | pv | dd of=/file
Здесь мы выдаем содержимое нужного нам файла на стандартный вывод, передаем утилите pv, а затем она отдает его другой утилите, которая уже выполняет запись в файл. Для cp такое сделать не получиться, но мы можем поступить немного по-другому:
# pv /ваш_файл | cat > новый_файл
Готово, здесь мы тоже получим прогресс команды копирования.
Перенаправить вывод в файл
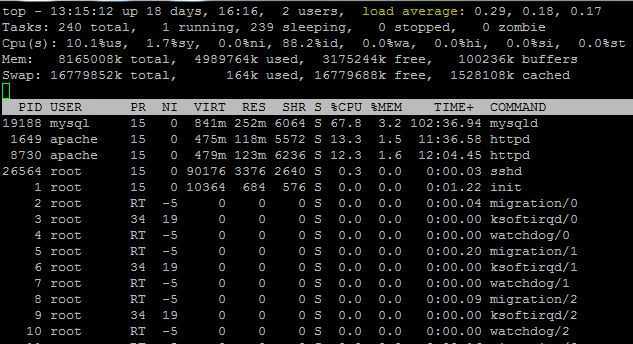
Все очень просто. Вы можете перенаправить вывод в файл с помощью символа >. Например, сохраним вывод команды top:
Опция -b заставляет программу работать в не интерактивном пакетном режиме, а n — повторяет операцию пять раз, чтобы получить информацию обо всех процессах. Теперь смотрим что получилось с помощью cat:
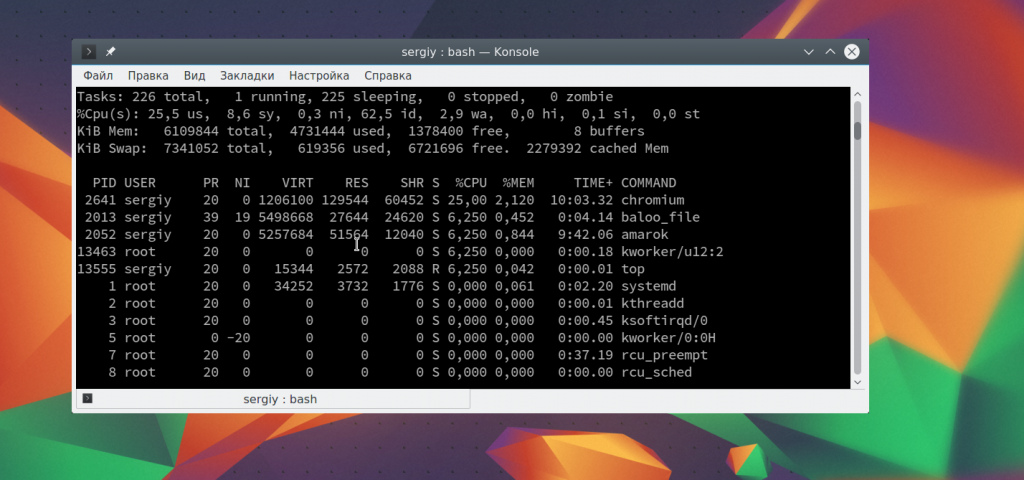
Символ «>» перезаписывает информацию из файла, если там уже что-то есть. Для добавления данных в конец используйте «>>». Например, перенаправить вывод в файл linux еще для top:
По умолчанию для перенаправления используется дескриптор файла стандартного вывода. Но вы можете указать это явно. Эта команда даст тот же результат: